



热门搜索
- 超多方言实时语音识别
- AIGC
- 语义大模型
- 智能体平台


 新闻详情
新闻详情ACL 2026 | Xingchen AGI:破解精准翻译难题——双轨推理构建AGI时代可控翻译新范式
通顺却失真:机器翻译的细节失守困局与根源破解
星辰通用人工智能实验室 (Xingchen AGI Lab)是中国电信星辰系列基础大模型的研发单位,将 “用国产芯片训出国际一流模型” 作为自己的使命目标,开展战略性、引领性、系统性的通用人工智能全栈技术研发,推动国产生态成为通用人工智能原始创新和规模应用的重要力量。

实验室于 2026 年 3 月在北京成立,历经前身近五年建设,团队成员超 230 人,平均年龄 31 岁,技术方向牵头人及骨干均毕业于清华、中科院、斯坦福、哥伦比亚等国内外知名高校,核心基模研发团队 90% 来自阿里、腾讯、百度等互联网大厂。
当前,实验室基于中国电信国产万卡集群,已完成视觉、语音、语义和多模态四大方向布局,模型参数覆盖十亿 / 百亿 / 千亿 / 万亿,在 GitHub、huggingface 等主流开源社区下载次数突破 60 万,入选 2025 年 “央企十大国之重器”。
一封发给海外客户的邮件 ——
译成了 https:// 开放人工智能.com/ 文档,客户一点,404。
一句给朋友首演的祝福 ——
"Break a leg!"
被译成了 "祝你摔断一条腿!",祝福秒变诅咒。
一段给工程师的安装指令 ——
pip install numpy 被译成了
"管道 安装 数字 Python" 代码直接跑不起来。
大模型时代,机器翻译的整句流畅早已不是问题,真正的险滩藏在细节里:网址、专有名词、代码、品牌、俚语、习语…… 这些该 "原样保留" 或 "精准转换" 的关键元素,恰恰是大模型最容易出现误改、漏译、幻觉等问题。
面向 AGI 时代机器翻译的核心需求 —— 如何让 AI 翻译既 “说得顺”,又 “译得准、守得住”?
星辰通用人工智能实验室提出面向翻译的 Agent 框架 ——CEMT(Controllable Element-Oriented Machine Translation),以「建模翻译关键元素 + 结构化语言推理 + 全流程过程监督」,为大模型翻译构建可解释、可控制的智能体执行流程。
在机器翻译领域最权威的年度评测与学术会议 WMT(Workshop on Machine Translation)23/24 中英权威测试中,基于 7B 轻量基座的 CEMT 表现亮眼:双向翻译得分登顶 7B 级开源模型榜首,中译英平均得分 61.39 超越 7B 量级竞品,英译中得分 62.65 逼近 GPT-4o 等闭源模型;
近日,该研究成果已正式入选国际顶级会议 ACL 2026。审稿人一致给予高度评价,认为该工作从元素规范与推理过程监督角度重新定义了可靠机器翻译的实现路径,有效解决了特殊元素易误译、易篡改、易产生幻觉的行业痛点,对推动高可信、高可控 AI 翻译智能体的发展具有重要意义。
通顺却失真:机器翻译的细节失守困局与根源破解
主流机器翻译模型普遍存在痛点:译文语法通顺、语义合理,却在 URL、专有名词、文化习语等关键细节上频频 “失控”。在 WMT 权威测试集统计中,超 30% 的翻译错误均源于这类元素失真、语用误读问题。
这一问题的根源,在于翻译生成的底层逻辑缺陷:端到端黑盒生成模式既不识别关键元素,也不遵守规范准则;结果导向的强化学习奖励机制,更让模型靠篡改、误译等违规手段 “换” 高分,只学到表面语义相关性,而非规范执行的因果必要性。
这种底层错位,是微调或后处理无法弥补的。这也迫使我们重新思考:机器翻译不能只追求全局语义,提升可信翻译的关键,在于从根源重构推理与规范范式。
CEMT 的核心思路:用元素探测定规范,用双轨推理保可信
有了上述判断,如何让翻译既守住关键元素、又遵循规范可靠生成?CEMT 用一套两阶段 agent 框架给出解决方案:先做元素检测识别规范,再做结构化推理完成翻译。
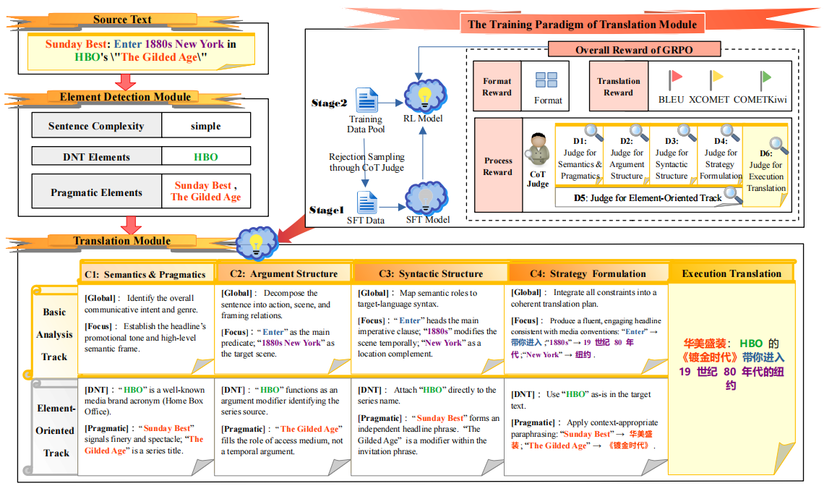
阶段 1:一键锁定翻译规范红线
CEMT 首先启动元素检测模块,对源文本进行显式式语言分析,一次性抽取三类核心信息并生成结构化规范集,为后续翻译划定清晰 “红线”:
一是句子复杂度等级,用于自适应控制后续推理的深度与强度;
二是DNT元素,如 URL、代号、标识、代码片段等,要求严格逐字保留;
三是语用敏感元素,如俚语、习语、文化特定表达,需按上下文做功能等价转换。
阶段 2:双轨推理 + 过程监督保质保真
在元素检测模块输出的结构化规范基础上,CEMT 进入核心的翻译模块,采用双轨四步结构化语言推理完成翻译生成:
一条是基础语言分析轨,根据句子复杂度自适应调整分析深度,完成语义、语用、论元结构与句法结构的常规解析;另一条是面向元素控制轨,专门针对不可翻译元素与语用元素进行针对性推理,确保关键内容严格保留或精准转换。整个推理按语义语用分析 → 论元结构分析 → 句法结构分析 → 翻译策略制定四步有序执行。
同时,CEMT 在强化训练中除了使用常见的格式奖励和译文奖励,还设计CoT Judge 思维链评判器对推理过程的完整性、元素处理的准确性、推理与译文的一致性进行过程级监督与奖励,让模型不仅 “译得通顺”,更 “推理合理、规范兑现、细节保真”,从根本避免为了流畅而牺牲关键信息。
实验结果
一、细节与流畅度的双赢曲线
CEMT在WMT23 中→英、WMT24 英→中两大权威机器翻译基准测试集上展开全面评估,采用BLEU、COMETKiwi、XCOMET三项主流指标综合衡量翻译效果。实验结果显示,基于7B轻量级基座,在全部开源模型中取得双向翻译平均得分第一,显著超越 Hunyuan-MT、DRT、TAT-R1、mExTrans 等强基线。
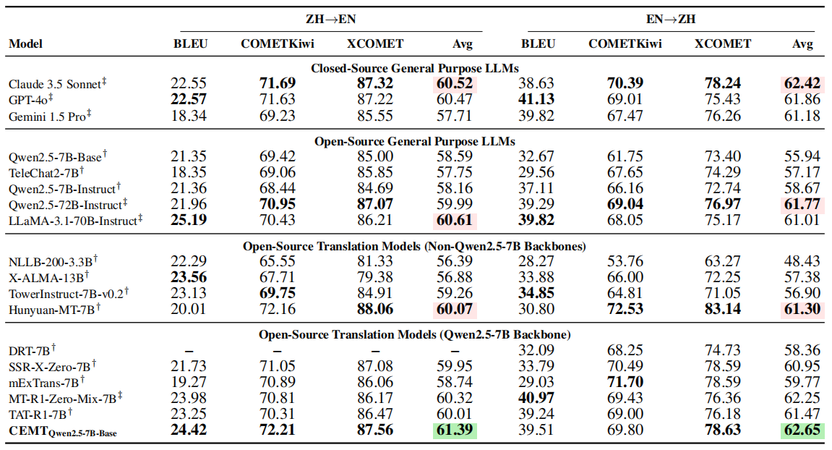
在元素级细粒度测试集上,CEMT 的优势进一步放大:在DNT子集上,模型实现了80.92% 的片段级精准保留率,大幅领先对比模型,从根本上减少 URL、标识、代码等内容的篡改与误译;在语用表达子集上,CEMT 同样取得最优 COMETKiwi 得分,有效避免生硬直译与语义偏差,真正做到 “保留该保留的、译准该译准的”。
整体而言,CEMT 不只是提升通用翻译流畅度,更在关键元素保真、规范合规性、翻译可靠性上实现质的突破,在小尺寸模型上实现了接近甚至超越顶尖闭源模型的综合表现。
二、语言无关的强通用性
为充分验证框架的语言无关通用性,对10 个覆盖高、中、低资源的语言对进行了无额外适配的测试,包括:英→德、英→西、英→日、英→俄、日→中等高资源方向,以及捷→乌、英→捷、英→印地、英→冰岛、英→乌克兰等中低资源方向。
实验结果显示,CEMT 在所有语言对上均展现出稳定的优势:在高资源语言对中,模型在 BLEU、COMET 等指标上全面优于同规模基线;在中低资源语言对上,其核心的元素检测与结构化推理机制依然有效,不可翻译元素保留率与语用表达翻译质量均显著提升。
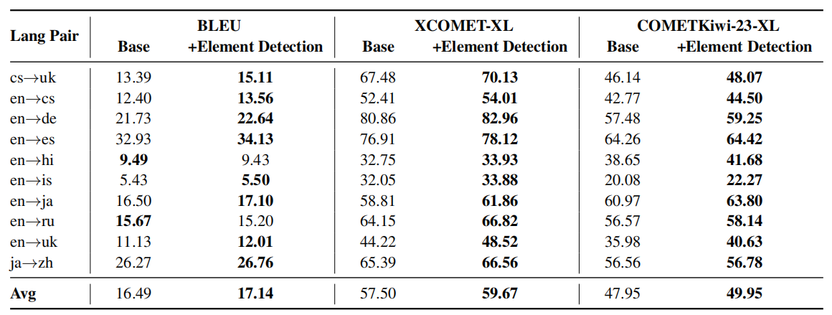
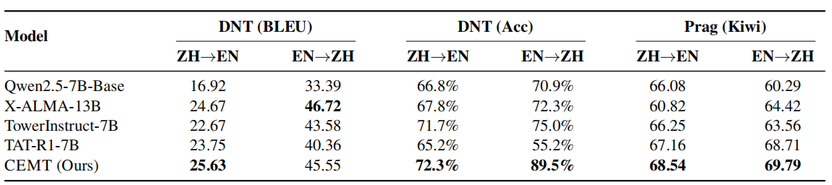
这一实验充分证明,CEMT 的元素检测 + 双轨推理核心机制不依赖于特定语言的句法特征,而是一种具备普适性的可控翻译范式,为低资源语言高质量翻译与多语种翻译系统构建提供了高效可行的解决方案。
结语
大模型翻译 “通顺却失真” 的根源,在于传统范式忽视元素规范,背离了 AGI 翻译智能体 “生成 + 守规” 的核心诉求。CEMT 通过 “元素探测 + 双轨推理 + 过程监督”,为翻译智能体构建 “感知 - 推理 - 反馈” 闭环,实现 “该留则留、该译则准”。
在大模型翻译迈向产业深水区、融入 AGI 生态的阶段,“可控性” 远比 “流畅性” 更重要。我们期待以 CEMT 为契机,推动可控翻译从 “后处理优化” 走向 “范式级重构”,让高可信翻译智能体惠及更多低资源语种与专业场景,为 AGI 时代跨语言协作筑牢根基。
