



热门搜索
- 超多方言实时语音识别
- AIGC
- 语义大模型
- 智能体平台


 新闻详情
新闻详情星辰通用人工智能实验室:5 篇论文入选国际顶会ACL 2026,获大会三赛道全球冠军
星辰通用人工智能实验室(Xingchen AGI Lab)是中国电信星辰系列基础大模型的研发单位,将“基于国产芯片训练国际一流大模型”作为自己的使命目标,开展战略性、引领性、系统性的通用人工智能全栈技术研发,推动国产生态成为通用人工智能原始创新和规模应用的重要力量。实验室于2026年3月在北京成立,历经前身近五年建设,团队成员超230人,平均年龄31岁,技术方向牵头人及骨干均毕业于清华、中科院、斯坦福、哥伦比亚等国内外知名高校,核心基模研发团队90%来自阿里、腾讯、百度等互联网大厂。当前,实验室基于中国电信国产万卡集群,已完成视觉、语音、语义和多模态四大方向布局,模型参数覆盖十亿/百亿/千亿/万亿,在GitHub、huggingface等主流开源社区下载次数突破60万,入选2025年“央企十大国之重器”。
近日,ACL 2026 公布录用结果,星辰通用人工智能实验室语义技术研发中心共计5篇论文被录用,同时获 ACL-SemEval2026 三赛道世界冠军。团队以星辰语义大模型 TeleChat 为底座,沿 AGI 相关技术路线,在语义基础大模型研发以及多项下游任务上推进算法创新。本次录用文章的方向覆盖MoE模型架构优化、机器翻译、表格理解等重要的AGI技术方向。
ACL(Annual Meeting of the Association for Computational Linguistics,国际计算语言学年会)由国际计算语言学协会主办,是计算语言学与 NLP 领域最具影响力的学术会议之一。ACL 2026 共收到 12148 篇投稿,经多轮评审,仅19% 被 Main Conference 录用,18% 被 Findings 录用。
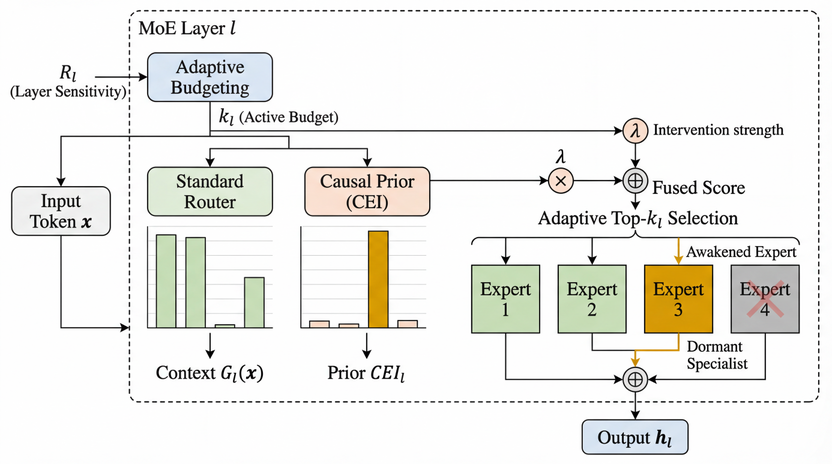
论文1:Awakening Dormant Experts : Counterfactual Routing to Mitigate MoE Hallucinations
摘要:在迈向AGI的征程中,提升语义基础模型在长尾知识场景下的推理可靠性是不可或缺的底层研发环节。 稀疏混合专家(MoE)架构是当前大模型扩展的主流,但其在处理长尾知识时极易产生事实幻觉。本文发现,这源于标准路由机制的“相关性-因果性错位”:路由器倾向迎合高频表层语法,导致真正掌握真理的“特长专家”因评分极低而陷入“沉睡”。为此,本文提出一种免训练的推理框架——反事实路由(CoR)。该方法通过离线扰动分析定位知识密集型网络层,为其动态倾斜计算预算;同时引入反事实专家影响(CEI)指标,精准量化并唤醒沉睡专家的因果价值。在推理阶段,CoR融合动态上下文与因果先验,零额外算力开销即可纠正路由偏见。实验表明,CoR在TruthfulQA等基准上准确率平均提升3.1%,为语义基础模型在高质量内容生成等重要下游场景中的可靠部署提供了先进解法。
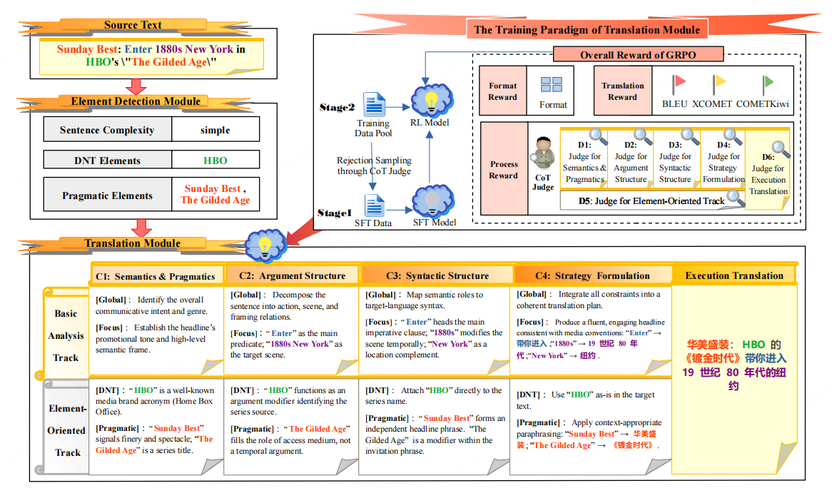
论文2:CEMT:Controllable Element-Oriented Machine Translation via Structured Linguistic Reasoning
摘要:
本工作为语义基础大模型(LLM)在AGI重要下游任务-机器翻译上实现精准可控的翻译提供了先进有效的解决方案。LLM在机器翻译中表现出色,能够处理复杂的句法与语义表达,但当输入包含需要严格保留或受控转换的翻译特定元素(如网址、俚语、习语及专有名词等)时,它们往往会出现转述错误、遗漏或幻觉,不仅降低翻译质量,更破坏关键细节的可靠性,难以满足高规范场景需求。为解决该问题,我们提出CEMT(Controllable Element-oriented Machine Translation)框架,其受人类翻译“分析-策略-生成”范式启发:首先通过元素检测模块精准识别并标记翻译特定元素,再通过翻译模块将翻译过程分解为语言分析、策略制定与译文生成,确保可控元素的可靠翻译。该框架通过分阶段设计,实现了可控元素翻译约束与整体译文流畅性的平衡。此外我们在训练中引入CoT Judge模型,对翻译各环节进行逐步监督,修正偏差以强化模型对约束的遵循能力。在WMT23/24中英双语基准测试中,CEMT在提升现有模型核心性能的同时,显著减少元素级约束违规,验证了其兼顾翻译质量与约束可靠性的有效性。相较于基线模型,CEMT在可控元素保留率上实现了明显提升,进一步证明了框架设计的合理性。
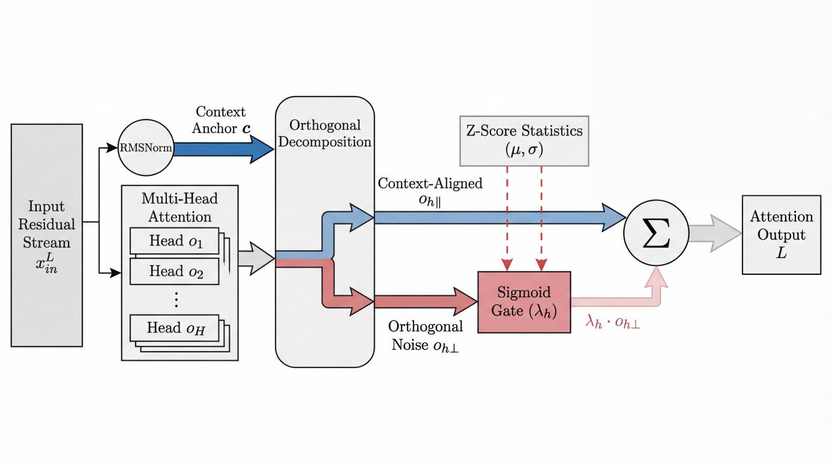
论文3:Hallucinations as Orthogonal Noise: Inference-Time Manifold Alignment via Dynamic Contextual Orthogonalization
摘要:赋予AGI系统绝对的事实忠实度与逻辑一致性,迫切需要我们在语义基础模型的内部表征优化上取得实质性突破。 现有的幻觉干预方法多停留在修改输出概率层面,而本文基于线性表征假说,对大模型幻觉提出了全新的几何解释:幻觉本质上是残差流中偏离上下文语义流形的“正交噪声”。当特定注意力头注入与上下文正交的异常成分时,就会引发内容的脱轨。为此,本文提出一种免训练的内部干预框架——动态上下文正交化(DCO)。该方法将当前层的输入残差流作为动态“锚点”,对各注意力头的输出进行精准的正交分解。为区分正常的语义发散与有害幻觉,DCO引入层级Z-Score动态抑制机制,利用门控网络柔性滤除表现为极端离群点的“正交分量”,并完全保留上下文一致性分量。实验表明,DCO在Llama-3上成功打破了“抑幻觉往往导致通用能力退化”的权衡困局,极大提升了语义基础模型在知识密集型问答等核心下游场景中的落地表现。
论文4:Region-based Reinforcement Learning for Table Understanding
摘要:本工作为构建具备大规模结构化数据理解能力的AGI提供理论基础,同时为语义基础模型提供经营分析等应用场景下的优化方案。本文提出一种基于“区域增强”的面向表格理解的强化学习框架,首创性地将“区域证据”整合进推理链,强制模型显式定位与任务相关的表格行列区域,从而显著增强表格QA任务的推理答案可靠性与忠实度。我们提出区域增强监督微调(RE-SFT)技术,结合文本描述、符号定位及程序化推理,引导模型精准识别表格的物理布局。我们还设计了表格感知组相对策略优化(TARPO)算法,利用混合奖励系统动态平衡区域定位精度与逻辑推理的正确性。该方法不仅大幅提升了复杂表格问答的准确率,还通过证据定位机制极大增强了模型决策的可解释性。
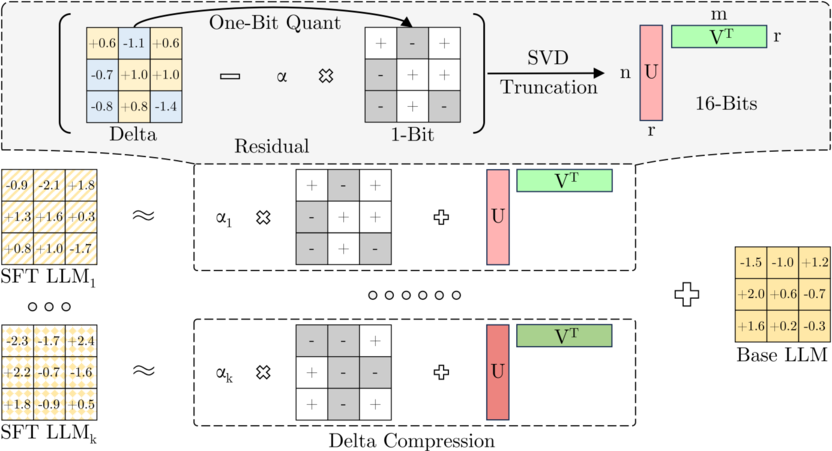
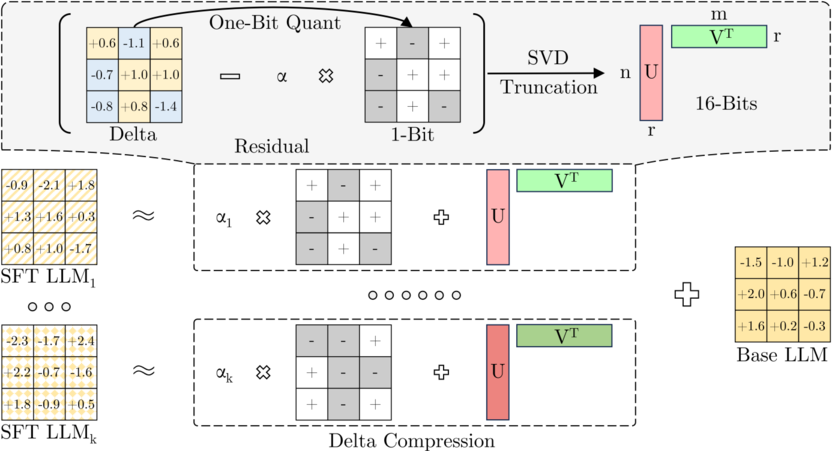
论文5:D-QRELO: Training- and Data-Free Delta Compression for Large Language Models via Quantization and Residual Low-Rank Approximation
摘要:构建AGI离不开语义基础模型在各垂直领域的大规模专业化微调,但这同时也带来了沉重的多模型部署显存负担。尽管增量压缩是缓解该压力的有效途径,但本文发现:在大规模数据微调下(如DeepSeek-R1-Distill),增量参数的数值与信息熵会急剧膨胀,致使现有压缩方法性能严重衰退。为此,本文提出免训练的增量压缩框架D-QRELO。该方法创新性地采用两阶段策略:先通过1-bit量化压制庞大的数值范围,随后应用残差低秩近似(SVD)精准恢复细节,从根本上规避了绝对误差的累积。在复杂推理任务中,D-QRELO在1/8高压缩率下保留了约94%的性能,以数倍的显存节省打破了现有SOTA的局限,为基础大模型的低成本泛化提供了新思路。
———— ACL-SemEval2026 三赛道世界冠————
赛道1:ACL-SemEval Task3 对话意图理解
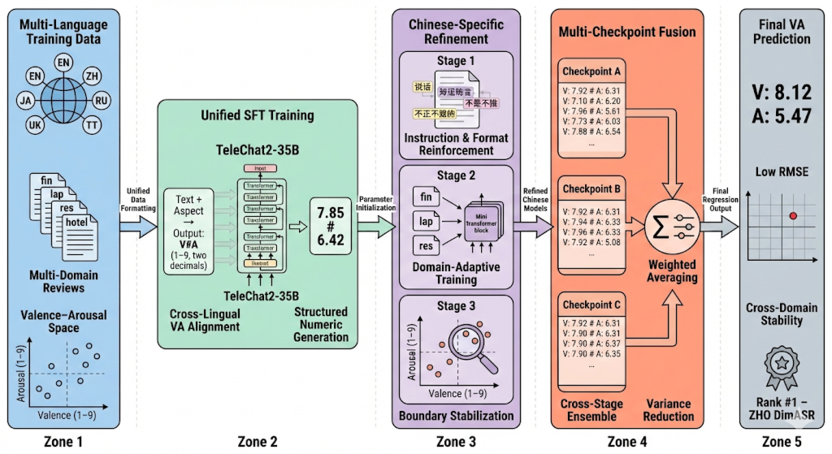
方面级情感分析是对话意图理解的关键组成部分,虽然该领域已历经多年技术积累和发展,但现有方法仍普遍受限于离散标签带来的粗粒度表征问题,难以实现精细化的语义理解。如用户说的「还行」「不太行」「完全不行」,如果只用离散标签(好/中/差),很容易丢掉程度、否定和语气里的细粒度信息。SemEval-2026 Track A(Dimension-based Sentiment Analysis)旨在突破传统方面级情感分析中离散标签的粗粒度局限,准确捕捉程度副词、否定结构、隐性情绪偏移等复杂语义现象,应对多领域分布差异以及跨语言带来的泛化挑战,具有极高难度与实用价值,StarAGI团队在中文子任务中排名第一,本工作是AGI的一部分,是为了AGI在现实世界的场景中应用更好,也是语义基础模型在对话意图理解中实际应用的效果的体现。
技术方案:
我们设计了一套基于自研星辰大模型(TeleChat2系列)的结构化数值生成框架,并提出一种全语种通用对齐与中文领域精炼相递进的多阶段训练方案。具体训练流程分为三个核心阶段,每阶段均围绕泛化稳定性与领域适应性进行系统设计:第一阶段:全语种联合训练,基于星辰语义大模型TeleChat2-35B,对全语种(英、中、日、俄、乌)与多领域(餐饮、数码、酒店、金融)数据进行统一监督微调,构建跨语言共享的情绪维度表征空间。本阶段不追求对特定语种的过拟合,而是通过大规模指令格式化学习情绪极性、强度、激活度的通用映射,为后续中文定向训练提供稳健的参数初始化与跨域/跨语泛化基础。第二阶段:中文领域定向训练,在全语种联合训练基础上,针对中文数据开展多层级递进式精炼。通过通用对齐+领域精炼的路径,模型在保持跨域鲁棒性的同时,显著提升中文三域的VA回归精度与数值稳定性。第三阶段:多模型融合与推理集成,针对DimASR评测指标RMSE对数值偏差高度敏感、单一模型易波动的问题,引入多模型融合策略。该融合机制有效缓解边界样本的单点预测风险,使整体RMSE在中文子任务一赛道中达到最优水平,为最终榜单平均成绩领先提供关键支撑。本工作是AGI的一部分是为了AGI在现实世界的场景中应用更好,也是语义基础模型在对话意图理解中实际应用的效果的体现。
赛道2:ACL-SemEval Task6 用户态度识别
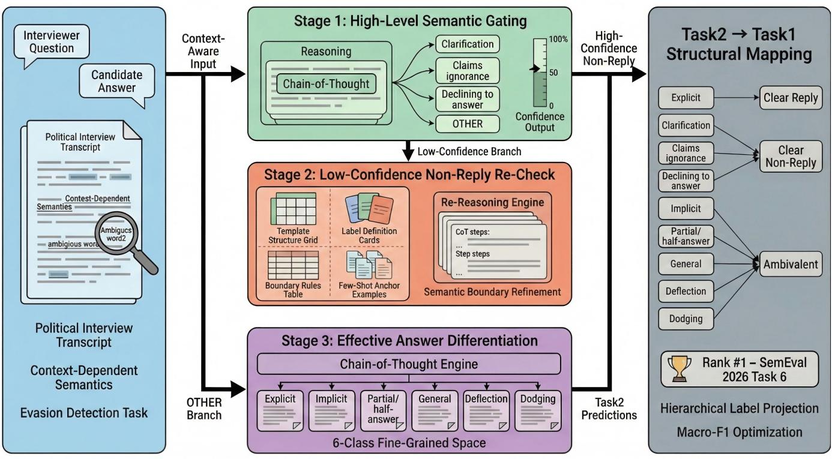
SemEval-2026 Task 6(CLARITY)聚焦政治访谈中受访者的回答回避态度识别,包括是否真实回答问题及采用的回避策略,需精准区分模糊表达等隐性规避情况。StarAGI 团队在两项子任务的公开榜单上均排名第一。
技术方案:
SemEval-2026 Task 6(CLARITY)包含两个关联子任务:任务一为对话态度识别,需对受访者是否真正回答问题进行三分类,具体分为Clear Reply(明确回答)、Clear Non-Reply(明确回避)、Ambivalent(模糊态度);任务二为回避类型细分类,涵盖Clarification(反问澄清)、Claims ignorance(表示不知情)、Declining to answer(明确拒绝)等九类具体回避策略。不同于常规将两任务独立建模的思路,我们设计了联合两任务的层级式识别方案,并提出一种基于思维链(Chain-of-Thought)的置信感知多阶段推理框架。该框架采用“先细后粗”的逻辑,先完成Task 2的细粒度回避类型推理,再通过预设的结构映射规则得到Task 1结果——Explicit映射为Clear Reply,Clarification、Claims ignorance、Declining to answer映射为Clear Non-Reply,其余类别映射为Ambivalent,使Task 1成为Task 2推理结果的结构投影,从语义层级上保证两任务的一致性。框架的三阶段递进推理贯穿置信度感知与动态重构逻辑,依次完成高层语义门控、置信度驱动的动态重构推理、有效回答细粒度区分,实现从粗粒度语义筛选到细粒度类型识别的逐步优化,提升整体识别精准度。本工作不仅为复杂对话场景下的细粒度语义识别提供了高效可行的技术方案,更为语义基础大模型在对话理解任务中的优化提供了新思路,同时为构建具备精准语义理解与复杂推理能力的AGI奠定了重要的技术与理论基础。
赛道3:ACL-SemEval Task13 生成代码检测
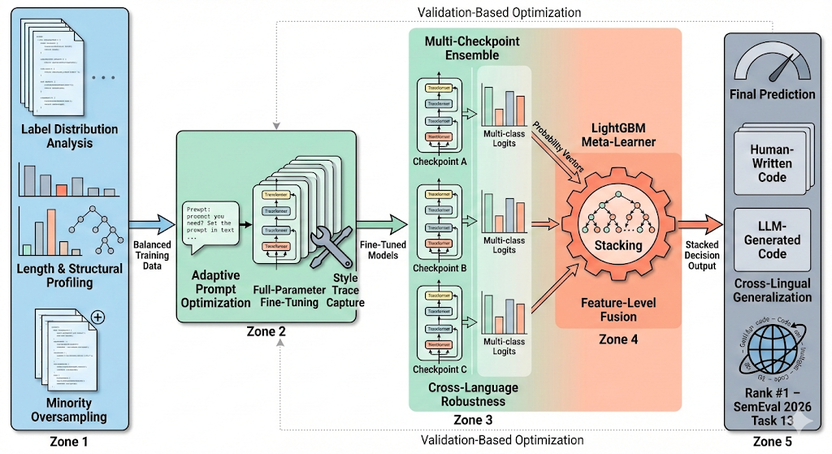
随着生成式大模型能力提升,机器生成代码在质量与风格上已高度接近人类代码,给学术诚信、招聘评估与软件安全带来挑战。现有检测方法在跨语言、跨模型与真实复杂场景中的泛化能力不足。为此,SemEval-2026 Task13 聚焦构建更鲁棒的机器生成代码检测与作者溯源能力。StarAGI 同时参与“Binary Machine-Generated Code Detection”和“Multi-Class Authorship Detection”两项评测赛道,均获得全球第一名。
技术方案:
为构建高可靠、可泛化的代码理解与判别能力,本工作从语义基础模型在关键下游安全场景的优化出发,为可信AGI系统中的生成内容检测能力提供重要支撑。现有机器生成代码检测方法在跨语言、跨生成器及复杂编程风格下泛化能力有限,难以稳定捕捉隐式生成特征。为此,本文提出统一判别增强框架 CodeDet-LLM,从数据分布建模、判别能力增强与多模型融合三个层面系统提升检测性能。首先,对训练数据的标签分布、代码长度与结构特征进行建模,并结合针对少数类别的数据增强策略,有效缓解类别不平衡问题;其次,构建任务自适应提示优化与全参数微调机制,引导模型学习细粒度风格差异与潜在生成痕迹;最后,引入多 checkpoint 集成与跨模型预测融合方法,并基于验证集进行 LightGBM stacking 学习,实现多源判别信号的高效整合。实验表明,该方法在跨语言与多生成器场景下均具备优越的鲁棒性与泛化能力,在"Binary Machine-Generated Code Detection"与Multi-Class Authorship Detection”两个赛道中均取得最优性能,验证了所提框架在生成代码检测领域的有效性与先进性。
星辰语义基础大模型TeleChat已开源1B、3B、7B、12B、35B、36B、39B(MoE)、52B、105B(MoE)、115B的不同参数模型的训练和推理代码,链接如下:
https://github.com/Tele-AI
https://huggingface.co/Tele-AI
https://modelscope.cn/organization/TeleAI
https://modelers.cn/user/TeleAI