



热门搜索
- 超多方言实时语音识别
- AIGC
- 语义大模型
- 智能体平台


 新闻详情
新闻详情TeleAI 提出探索驱动的对齐方法 COPO,用好奇心让小模型“逆袭”大模型
“神之一手”是围棋棋手的毕生追求,但“神之一手”从来都不在棋谱中。
将棋谱熟记于心,只是成为大师的门槛。而在面对陌生的棋局时,能基于棋谱的训练,探索出人意料的下法,才是通向“神之一手”的关键。智能的涌现需要“好奇心”——既能巩固已知,又能主动探索未知,触类旁通。

如今的大语言模型也面临类似的困境:它们依赖于人类提供的偏好数据集,一旦超出训练范围,表现就会大打折扣。
为了解决这一困境,中国电信集团 CTO、首席科学家、中国电信人工智能研究院(TeleAI)院长李学龙教授带领团队,联合多家顶尖机构提出了一种新的探索驱动的大模型对齐方法 Count-based Online Preference Optimization(COPO),让模型像人类一样“主动探索”,甚至让一个仅有 80 亿参数的小模型在性能上超越了 700 亿参数的“巨无霸”。这项成果已被国际顶级会议 ICLR 2025 收录,成为 AI 对齐领域的重要突破。

论文地址:
https://arxiv.org/abs/2501.12735
开源代码:
https://github.com/Baichenjia/COPO
这一创新成果也为智传网(AI Flow)中 “基于连接与交互的智能涌现” 提供了重要技术支撑,使模型在动态交互中不断学习和进步,在探索中实现智能的持续涌现。
中国电信人工智能研究院(TeleAI)正在加速推进“智传网 AI Flow”的研究工作,并与智能体、智能光电、AI 治理形成“三智”+“一治”的完整战略布局。


大型语言模型(LLM)需要通过“对齐”来理解人类价值观。传统方法依赖人类反馈强化学习(RLHF)——人类标注哪些回答更好,模型据此调整策略。但模型对数据集“习题库”之外的语言难以进行有效泛化。
因此,为了让大语言模型在训练时像人类一样主动探索未知领域,大模型相关研究开始由人类反馈强化学习驱动的离线对齐(Offline RLHF)转向“在线对齐”(Online RLHF)
TeleAI 提出的 COPO 算法,正是为了解决“在线对齐”过程中的核心问题:如何使 LLM 在每次迭代中,有效地探索【提示-回复】空间,从“被动学习”到“主动探索”,扩大偏好数据覆盖范围,提高模型对人类偏好的学习和适应能力。
基于大模型奖励的线性假设,团队将奖励函数简化为参数向量和特征向量的内积形式。在此假设下,可以将复杂大模型对语言提取的特征作为一个低维的向量,将 RLHF 过程中构建的显式或隐式的大模型奖励视为向量的线性函数。

在此基础上,给定大模型偏好数据集
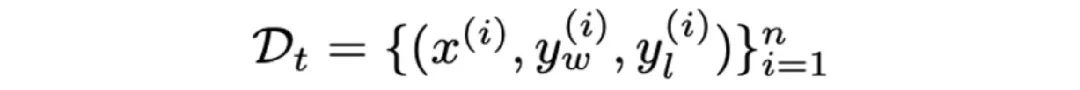
在现有 Bradley-Terry (BT) 奖励模型的基础上可以通过极大似然估计来估计奖励模型的参数,即:
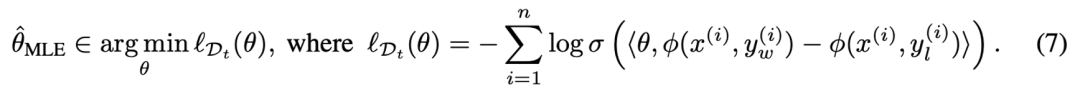
随后,可以定量地为奖励模型提供一个明确的误差界限,并得到关于奖励模型参数的置信集合(confidence set),从而使估计的参数以较大概率落在置信集合中,即:
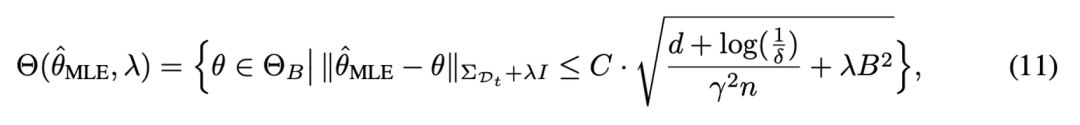
随后,在参数集合中可以使用乐观的期望值函数来获得值函数估计的置信上界,从而实现了强化学习探索中的乐观原则(Optimism), 使大模型策略向乐观方向进行策略优化。
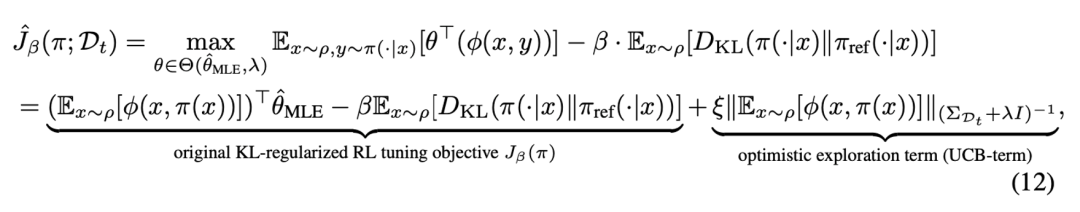
最终,优化项包含两个部分:
已知偏好奖励:鼓励模型生成符合人类已有偏好的回答(如礼貌、准确)。
探索奖励:如果模型尝试了之前很少生成的回答,即使不确定是否最优,也会获得额外加分。这类似于老师鼓励学生尝试新解法。
这将有助于大模型在最大化奖励和探索新响应之间的权衡,即著名的强化学习【探索 - 利用权衡】(exploration-exploitation trade-off)。
最终,研究证明了采用 COPO 算法的在线学习范式能够在 T 次迭代后,将总后悔值限制在 Õ (√T) 的量级内,显示了算法在处理大规模状态空间时的效率和稳定性。

团队在算法设计中结合了直接偏好优化(DPO)的算法框架。其中第一项对奖励的构建和奖励最大化的学习,具象化为 DPO 的学习目标,而将乐观探索的 UCB 项转化为更容易求解的目标。
在有限状态动作空间的假设下,乐观探索项可以表示为基于“状态-动作”计数(Count)的学习目标,即
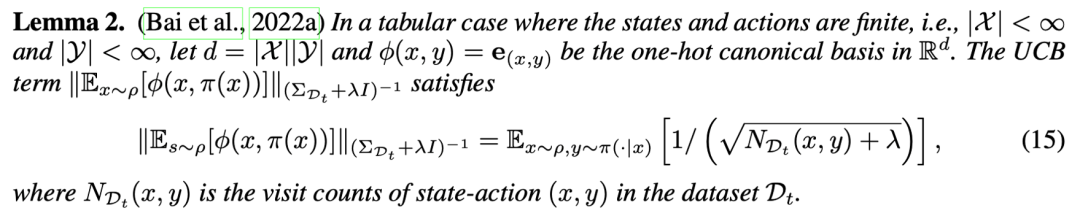
从而,最终的学习目标表示为 DPO 奖励和基于“提示-回答”计数的探索目标。
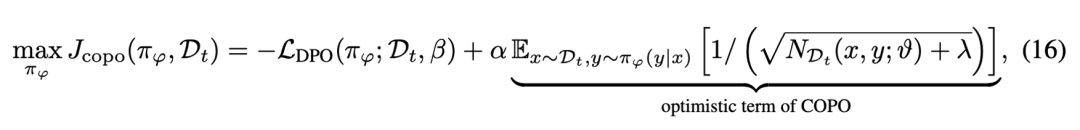
上式中第二项通过在偏好数据中对模型产生的“提示-回答”进行计数,可以鼓励增加对之前出现次数较少的“提示-回答”的探索,来鼓励大模型突破离线数据集的覆盖,使模型主动探索新的、可能更优的回复,从而在迭代过程中扩大数据覆盖范围并提高策略的性能。
进而可以通过求解梯度的方式进一步解析 COPO 优化目标的意义:
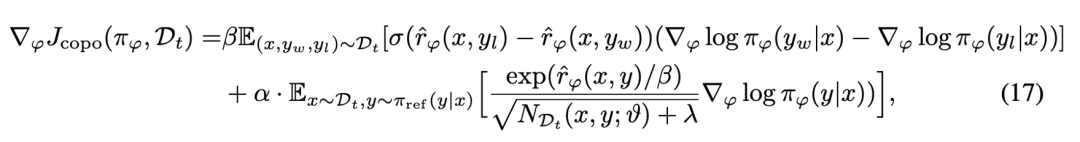
由两部分组成:第一部分负责优化模型以最大化偏好数据上的预期奖励;第二部分对应于探索项的梯度,它根据“提示-回复”对的历史访问次数来调整模型的优化方向。
当某个回复的历史访问次数较少时,该项会推动模型增加生成该回复的对数似然,从而鼓励模型探索那些较少被访问但可能带来更高奖励的区域,使算法能够在最大化奖励的同时有效地平衡探索与利用,实现更优的策略学习。
但语言的可能性几乎是无限的,如何记录哪些回答被“探索过”?COPO 设计了一个轻量级的伪计数模块(CFN)予以解决。
CFN 的基本假设是,计数可以通过从 Rademacher 分布的采样来估计得到,考虑从 {-1,1} 的集合中近似随机采样得到的分布,如果进行 n 次采样并对采样结果取平均,则该变量的二阶矩和计数的倒数呈现出等价的关系,即
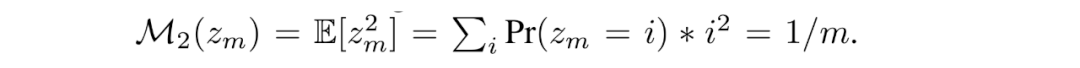
进而,CFN 通过在每次遇到状态时进行 Rademacher 试验(即硬币翻转),并利用这些试验的平均值来推断状态的访问频率。在实现中,CFN 表示为一个轻量化的网络,它通过最小化预测值和实际 Rademacher 标签之间的均方误差来进行训练。
并且,CFN 接受由主语言模型提取的“提示-回复”对的最后隐藏状态作为输入,并输出一个预测值,该值与状态的 “伪计数” 成反比。通过这种方式,CFN 能够为每个“提示-响应”提供一个探索激励,鼓励模型在探索迭代中扩大数据覆盖范围,提高模型对齐的性能。
在实验中,团队使用 UltraFeedback 60K 偏好数据集来对 Zephyr-7B 和 Llama3-8B 模型进行微调,数据集中包含丰富的单轮对话偏好对的数据。
实验中使用了一个小型的奖励模型 PairRM 0.4B 来对多轮迭代过程中模型生成的回复进行偏好排序,从而在探索中利用不断更新后的大模型来产生不断扩充的偏好数据,提升了数据集的质量和覆盖率。
此外,实验中使用轻量化的 CFN 网络实现对“提示-响应”对的伪计数,大幅提升了在线 RLHF 算法的探索能力。
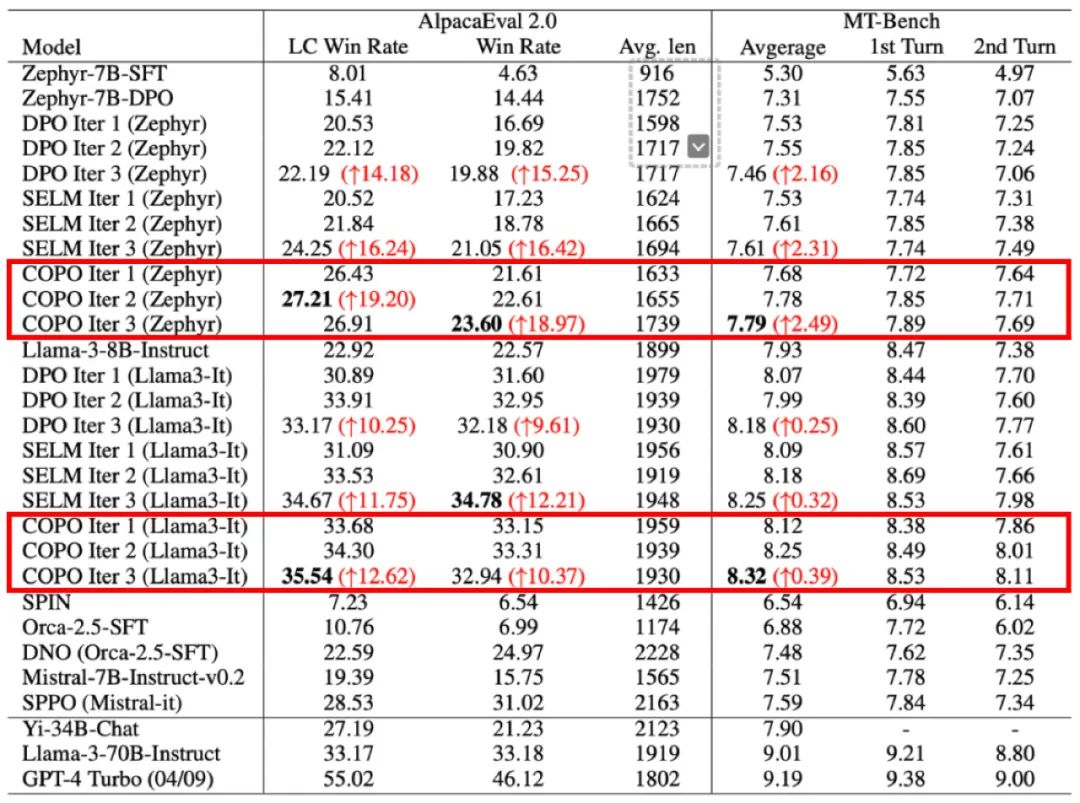
实验结果表明,COPO 算法在 AlpacaEval 2.0 和 MT-Bench 基准测试可以通过多轮探索和对齐来不断进行性能提升。
相比于离线 DPO 算法,COPO 显著提升了 Zephyr-7B 和 Llama3-8B 模型的 LC 胜率,分别达到了 18.8% 和 7.1% 的提升,验证了 LLM 探索能力提升对获取更大数据覆盖和最优策略方面的优势。
此外,COPO 超越了在线 DPO、SELM 等当前最好的在线对齐方法,以 8B 的模型容量超越了许多大体量模型(如 Yi-34B,Llama3-70B)的性能,提升了大模型在语言任务中的指令跟随能力和泛化能力。
COPO 通过赋予大模型「探索好奇心」,打破了传统 AI 依赖静态数据被动学习的桎梏,推动了模型从「数据驱动」向「探索驱动」的进化。
这不仅提升了现有模型的效率和性能,还为未来构建更自主、更通用的 AI 系统提供了关键技术路径。