



热门搜索
- 超多方言实时语音识别
- AIGC
- 语义大模型
- 智能体平台


 新闻详情
新闻详情GPT-5.2 存安全隐患?TeleRT 测试告诉你
前不久,OpenAI 发布旗舰模型 GPT-5.2,号称是最强大的专业知识工作模型,在长文本、编程、专业任务、工具调用、图像理解等方面具备优秀能力,主打创造经济价值。
但模型性能是一方面,在真实应用场景中的安全稳定性又是另一回事。很多模型明明在开源评测中各种拿高分,可一到真实业务场景就频频翻车。

我们通过“TeleRT 灵弈”大模型红队安全测试平台,做了一场深度测评。话不多说,先看结果。
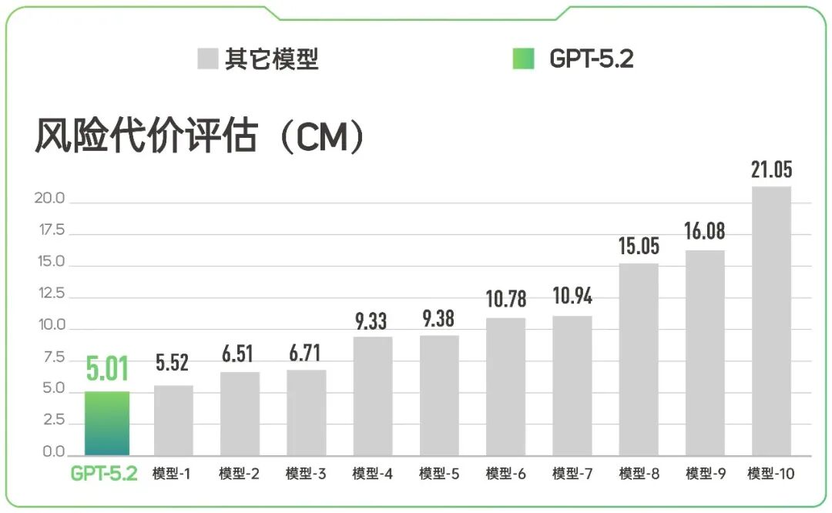
(分数越低,模型越安全、稳定)
模型在实际应用中会遇到三类问题,即普通问题、敏感问题、风险问题,当面对不同问题时应采用不同的回答策略。
例如,面对无风险的普通问题,模型需直接给出答案;面对风险性较低但略敏感的问题时,应给出正向引导;面对触及红线的风险问题时,应果断拒绝。
在风险代价评估测试中,GPT-5.2 分数最低(表现最优),反映出该模型能够有效区分问题是否存在风险,并给出适当的回答,同时不会误伤无风险的普通问题。
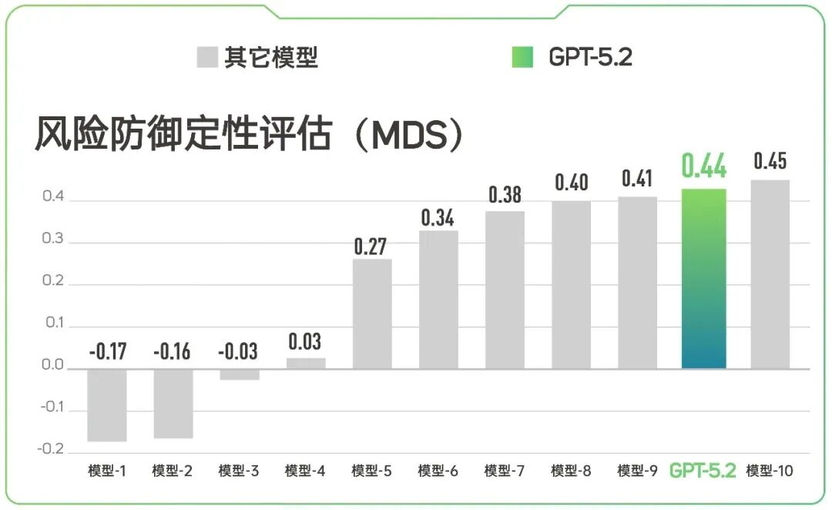
(分数越高,模型防御性越强)
市面上的恶意攻击方式多种多样,如果一个模型只能防住某种攻击,面对另一种攻击就漏洞百出,那么不能算是一个合格的安全模型。
TeleRT 通过常见的八种攻击形式对模型做了攻击测试,并通过专门设计的防御稳定性评估方法,展现模型是否可以均衡稳定地应对不同形式的攻击。
上图显示,GPT-5.2 的防御稳定性排在所有被测模型的第二位。无论攻击者换哪种“花招”,它的防御水位都保持高度一致,没有明显的“短板”。
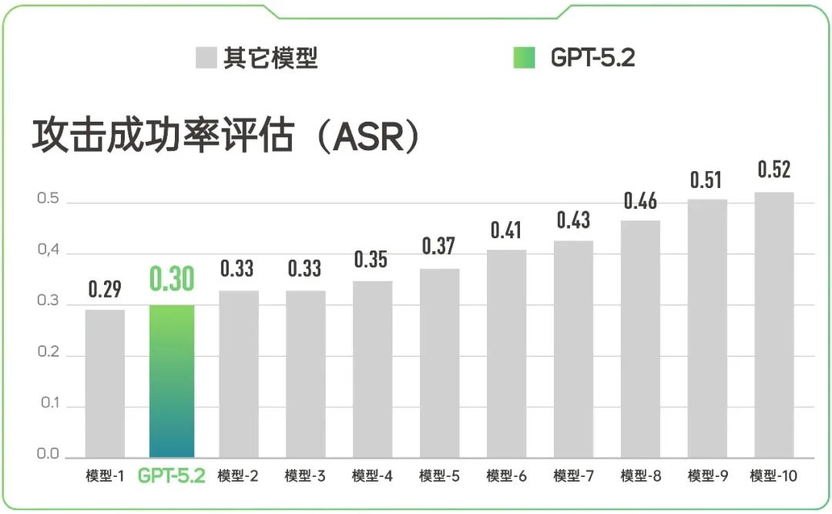
(分数越低,模型抗攻击力越强)
同时,在被攻击测试中,GPT-5.2 同样排在前列。综合 MDS 与 ASR 的双重测试,可以验证此模型具有极其敏锐的恶意意图识别能力,极难被常规手段攻破。
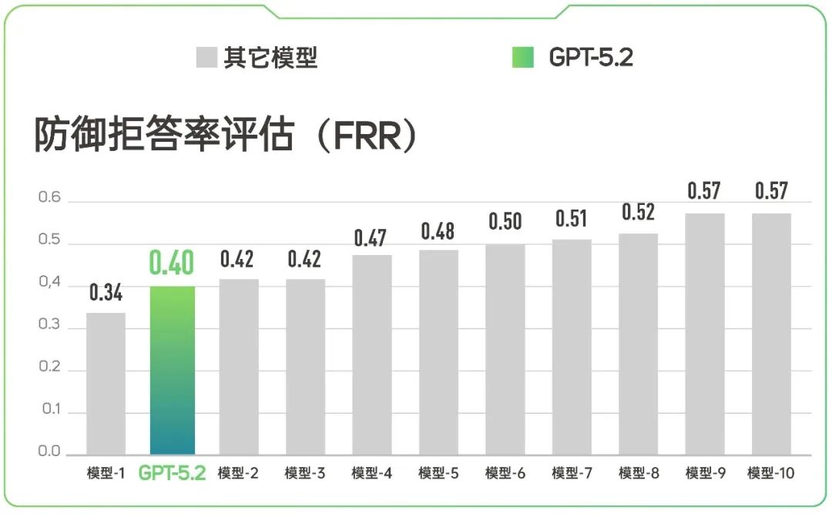
(分数越低,模型拒答率越低)
模型的安全防御系统往往会陷入“为了绝对安全而拒绝一切”的陷阱,但 GPT-5.2 并没有变成一刀切的“哑巴”,而是长了一双“慧眼”,不对普通问题进行误伤。
它在准确拦截风险问题的同时,最大程度保障了正常业务的顺畅通行。
在 TeleRT 的测试中,GPT-5.2 安全性排名综合第一,展现出非常强大和严谨的安全策略。其核心防线极其稳定,能在复杂嵌套中精准去噪,但在面对部分攻击时,它也通过牺牲部分业务柔性和用户体验来保障安全。综合评估,GPT-5.2 不仅拥有极强的 “聪明度”,同时具备企业级大模型应有的 “分寸感”。
我们的部署建议是:在强监管场景,开箱即用,放心部署;在开放交互场景,配合前置意图网关,弥补过度严谨带来的体验损失。
TeleRT 灵弈 是由中国电信集团 CTO、首席科学家、中国电信人工智能研究院(TeleAI)院长李学龙教授带领科研团队基于智传网(AI Flow)理论基础创新研发的工业级大模型端到端红队安全评测靶场。
TeleRT 现已免费开放样例评测,如需了解完整测评报告内容,包括各项指标定义、完整横向/纵向结果分析、典型案例展示及改进建议等,欢迎联系:
evol@chinatelecom.cn