



热门搜索
- 超多方言实时语音识别
- AIGC
- 语义大模型
- 智能体平台


 新闻详情
新闻详情大模型的“阿喀琉斯之踵”
系统警报!
某金融机构智能交易突然“卡死”
已排除光缆中断导致
也不是海量用户集中涌入
幕后黑手竟然是它——
一段精心伪装的“有毒文本”

有毒文本就像卡住紧密齿轮的一颗小石子
瞬间耗尽昂贵的 GPU 算力
让支撑关键业务的 AI 系统陷入瘫痪
这不是危言耸听,而是当大语言模型(LLM)成为现代计算基础设施核心后,不得不面对的严峻现实。近两年,全球多家主流大模型服务商频繁报告“大规模服务降级”事件,许多用户以为只是单纯的“服务器太忙”,但极可能是一场新型攻击演练。
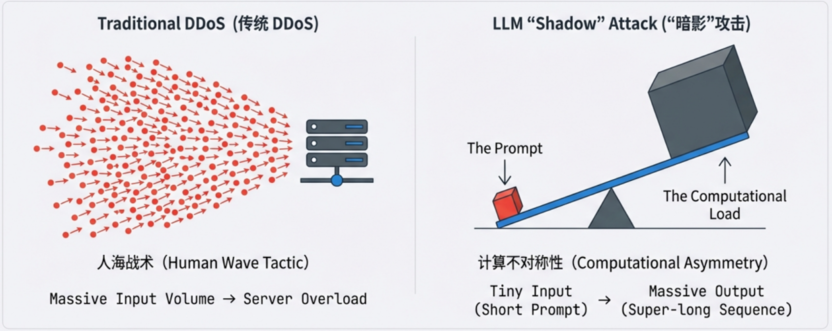
传统的 DDoS 攻击依靠“人海战术”淹没服务器,而在大模型时代,攻击者如同影子一般通过免费 API 悄悄渗入,利用推理过程中的“计算不对称性”,仅需发送极短的 Prompt,就能诱导模型生成超长序列,通过“四两拨千斤”的方式耗尽系统资源。
这就像是希腊神话中的“阿喀琉斯之踵”,成为大模型系统的“死穴”,虽然拥有每秒亿次计算的强大 GPU,却在资源调度上存在致命的结构性缺陷。

为此,中国电信集团 CTO、首席科学家、中国电信人工智能研究院(TeleAI)院长李学龙教授带领科研团队展开深入研究,以以智传网(AI Flow)理论框架为基础,首次系统揭示了大模型推理服务系统在面对极少量恶意流量时的脆弱性,并提出“暗影”大语言模型推理服务对抗性攻击评估框架与创新 DRouter 防御方法。
大模型的“阿喀琉斯之踵”
到底有多脆弱?
TeleAI 科研团队通过大量仿真实验,以量化的方式发现了大模型系统受到“暗影”攻击后的崩溃反应,呈现三个反直觉现象。
现象1:非线性崩溃
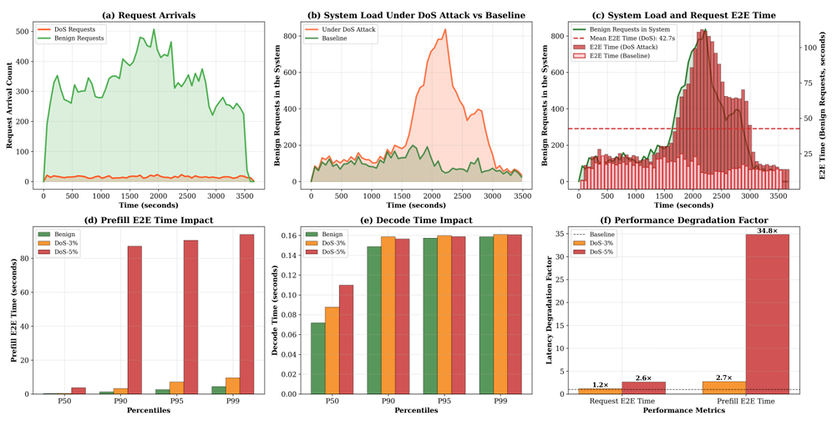
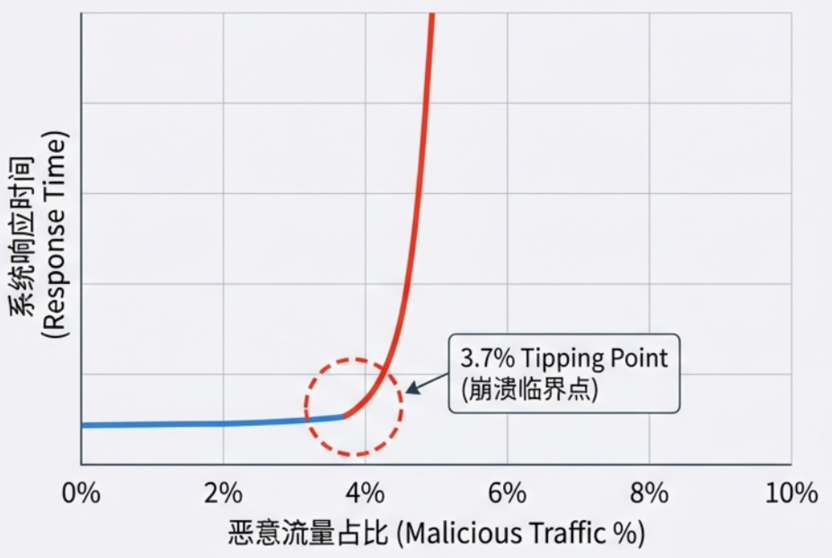
正常请求平均生成 211 个 Tokens,耗时约 30 秒;而恶意请求可诱导模型生成 3096 个 Tokens,占用时间长达 393 秒,资源占用呈倍增趋势。一旦恶意流量占比超过 3.7 %,系统的预填充时间就会激增,发生非线性崩溃,导致服务瘫痪。
现象2:连带伤害
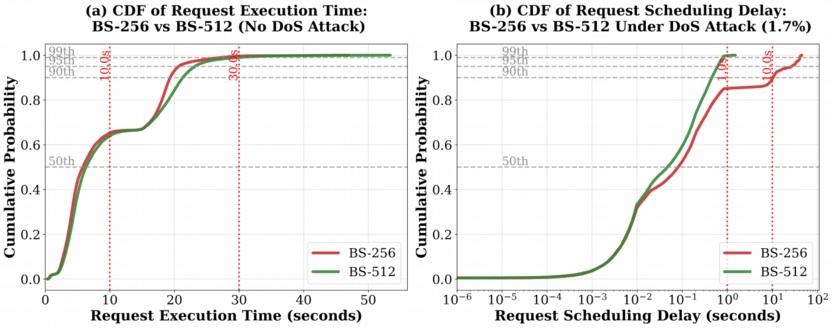
现有的大模型调度系统通常将预填充和解码阶段紧密耦合,而恶意请求一旦占据 Batch 中的位点,就会像“路霸”一样长时间不走,这将导致后续新来的正常请求只能在队列中无限等待,无辜躺枪。
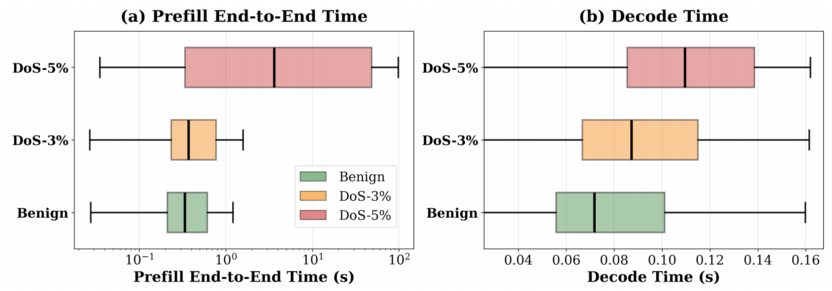

现象3:配置陷阱
那些在平时为了追求高性能而设置的“最优配置”(如 Batch Size 256),在面对攻击时反而最先崩溃。这表明,传统只关注“良性吞吐量”的配置思路,在安全视角下是极其危险的。
DRouter 防御策略
精准防御 降本高效
面对“影子”侵蚀,单纯堆算力无异于饮鸩止渴。为此,TeleAI 科研团队则提出了一种轻量级的防御策略——DRouter,在现有的路由器上增加了一个轻量级防御层,核心理念是在请求进入昂贵的 GPU 计算前,先进行一道“智能安检”。
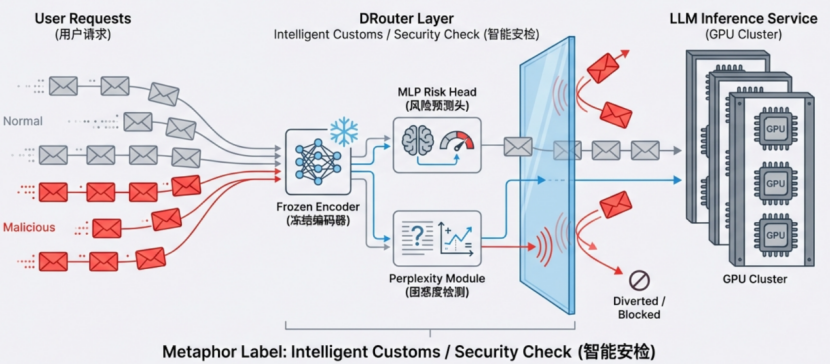

DRouter 包含一个冻结的编码器、一个轻量级MLP风险预测头,以及可选的困惑度检测模块。它将请求分为三类:

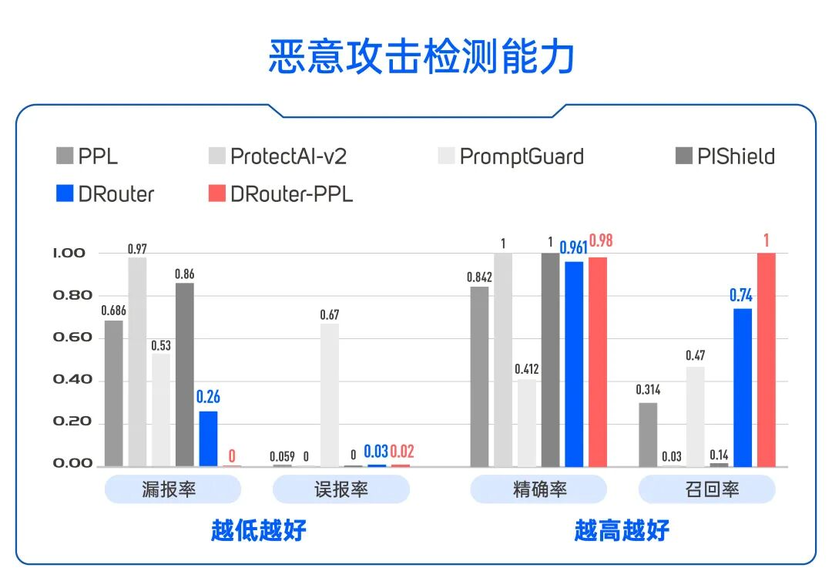
实验结果表明,DRouter 在检测恶意 Prompt 攻击方面达到 了 0.96 的精确度,误报率仅为 0.03,能够实现精准打击。
同时,相比于用大模型去检测大模型,DRouter 的训练成本降低了两个数量级,且推理延迟几乎可以忽略不计。
这项研究不仅揭示了大语言模型服务系统的脆弱性,更为大模型落地应用敲响了警钟,即在构建 AI 基础设施时,不能仅关注模型本身的价值观对齐,更需从系统架构层面(如调度器解耦、隔离路由)考虑安全性。
DRouter 的提出证明了通过轻量级、可插拔组件,可以在不牺牲服务效率的前提下,为大规模 AI 服务穿上一层“防弹衣”。