



热门搜索
- 超多方言实时语音识别
- AIGC
- 语义大模型
- 智能体平台


 新闻详情
新闻详情我思,故我在!TeleAI 构建高质量长时流式全模态第一人称评测基准 TeleEgo
“我思,故我在。”
法国哲学家笛卡尔于 17 世纪提出的这一著名哲学命题,将人的理性与自我意识确立为知识的起点,让人的“第一人称视角”成为近代哲学“主体性”理论的核心。到 18 世纪,德国哲学家康德进一步表达“‘我思’必须能够伴随我的一切表象”,认为第一人称的意识统一性是人获取知识的前提。

三百多年后的今天,人工智能也能模拟人类的第一视角,真正站在“人”的角度去认知、理解、思考现实世界中的真实场景。利用戴在人们身上的智能感知设备,“第一人称 AI 助手”需要实时响应处理视频、音频、文本等多种模态的信息,并随着信息量的增加记住数天内的事件进行个性化反馈。
由于现有评测基准通常只对第一人称 AI 助手的单一维度能力进行评估,缺乏多模态整合评估,因此无法对模型是否具备康德所说的“意识统一性”做出有效判断。为此,中国电信人工智能研究院(TeleAI)以智传网(AI Flow)理论为指导,提出了一个高质量的长时流式全模态第一人称评测基准 TeleEgo,评估在真实场景中 AI 助手的实用能力。
相关论文:
J. Yan et al., “TeleEgo: Benchmarking Egocentric AI Assistants in the Wild”, arXiv:2510.23981.
https://arxiv.org/abs/2510.23981
从“演示好看”走向“日常好用”
当人们在处理一件事情的时候,接收到的信息是多元的,并具有实时性、突发性,还可能与其他事项有所关联。例如做一道菜,既需要一边看菜谱,一边观察食材的状态,还需要关注水池中的流水声、油锅里的煎炸声,甚至想着酱油有没有过期、白糖放在哪个盒子里。一个好的 AI 助手应辅助人们实现这些能力。
然而,现有评测基准要么只测试 AI 的某一个能力,例如只测记忆力,不管反应速度;要么用的并非真实生活里的流数据,而是给 AI 看一段段单独的视频,不是像人一样实时看着、听着连续发生的事;要么只能测试短时间的任务,测得了记几分钟前的事,测不了记昨天的事。
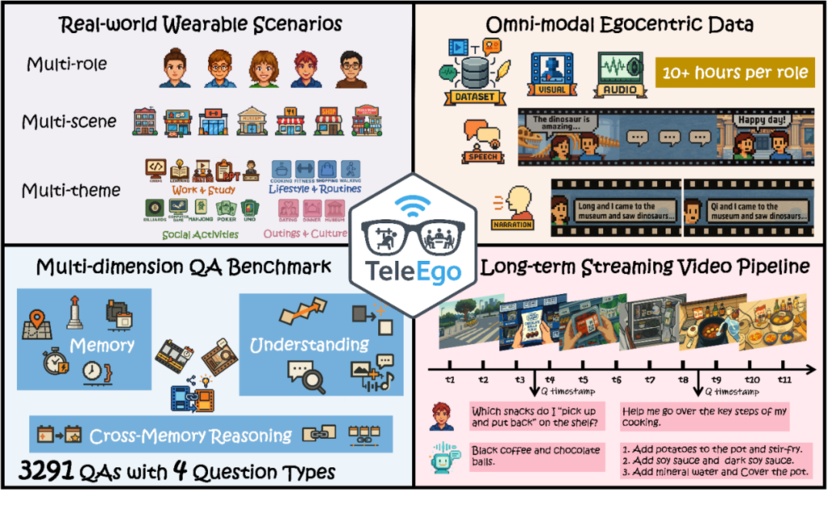
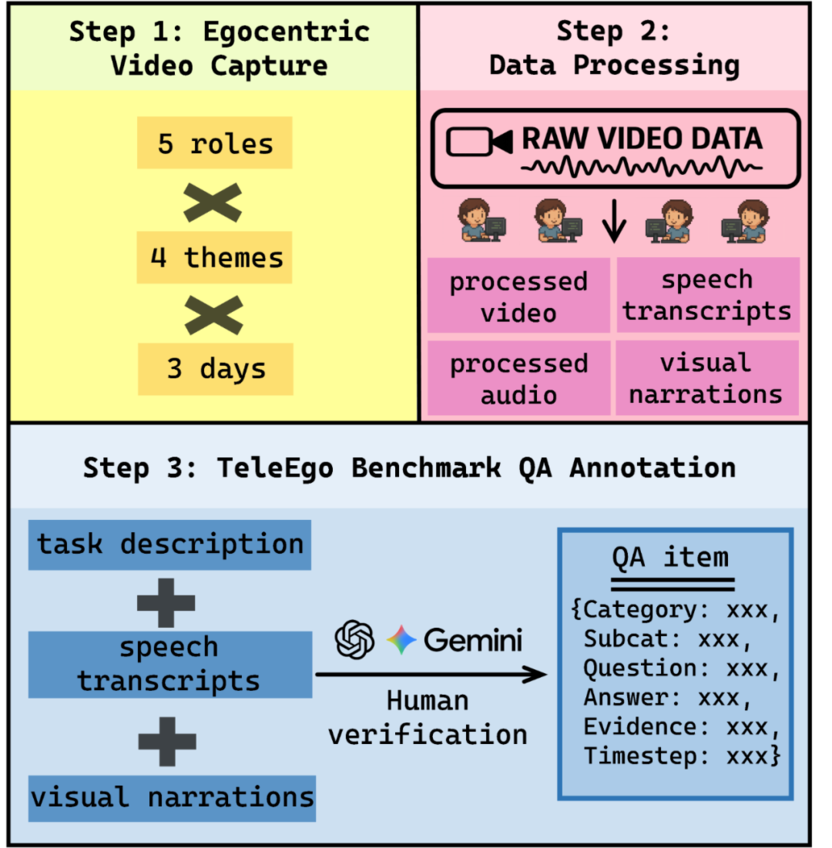
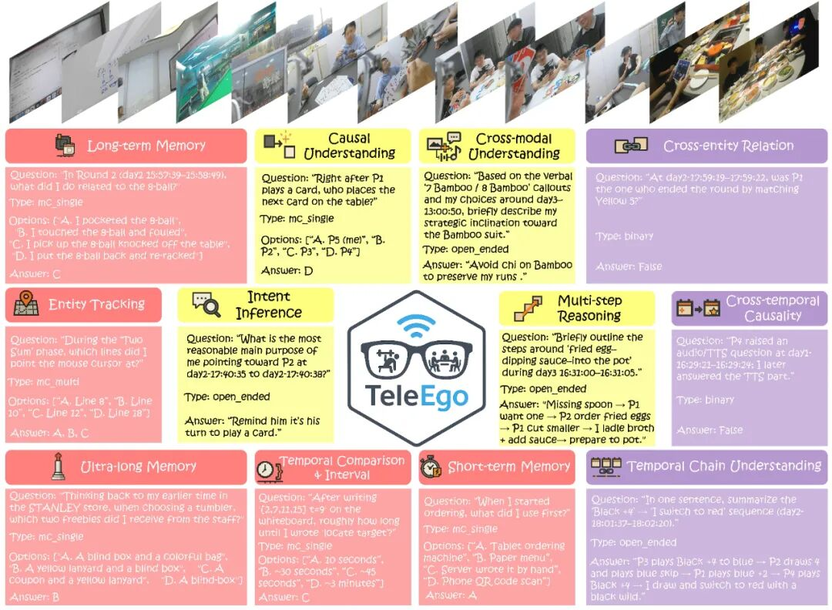
在 TeleEgo 的构建中,科研团队招募了 5 名志愿者,连续三天佩戴第一视角设备采集数据,覆盖四类日常主题,包括:工作与学习、生活与作息、社交与活动、文化与出行。其中,既有单人独处,也包含多人互动,并覆盖室内、户外、静态、动态及不同社交礼仪的等多种情境。
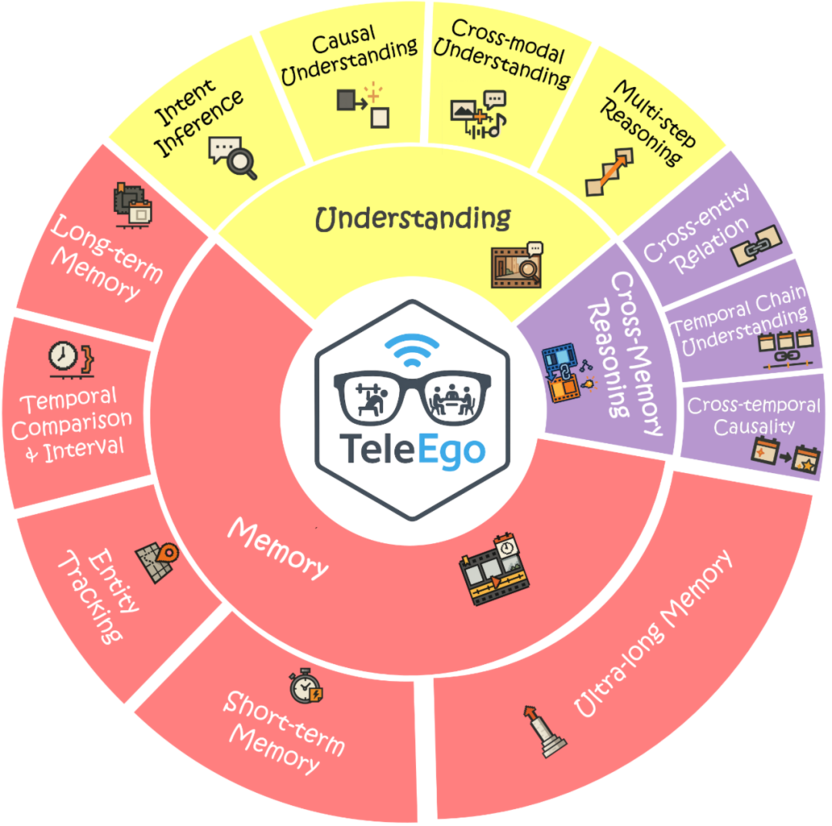
TeleEgo 围绕记忆能力(回忆过去事件)、推理能力(解释当前时刻),以及跨记忆推理能力(关联遥远事件)三个维度展开,并设计了 12 个细分子任务,涵盖从秒级到跨小时、跨天的记忆跨度,以及当下语义理解与跨时间、跨实体的推理整合。
记忆能力:检验时间一致性与状态演化表征,包括短期/长期/超长期记忆、实体跟踪、时间比较等。
理解能力:着重看清因果、听懂语境,包括意图推断、因果理解、跨模态理解等。
跨记忆推理能力:要求将远距事件串联为可验证的叙事,包括多步推理、跨实体关系、时间链理解、跨时因果等。
数据集还配备了 3291 项经人工核验的“考题”,其中记忆类任务占比 58.8%,理解类任务占比 27.3%, 跨记忆推理类任务占比 13.9%,包括选择、判断、开放多种题型。TeleEgo 严格执行在线流式评测,为每个题目设定统一的决策窗口,仅首次在窗口内给出正确答案才计分。
同时,TeleEgo 还引入两项核心指标。
第一,实时准确率(RTA)。衡量“在对的时刻说对的话”的比例。
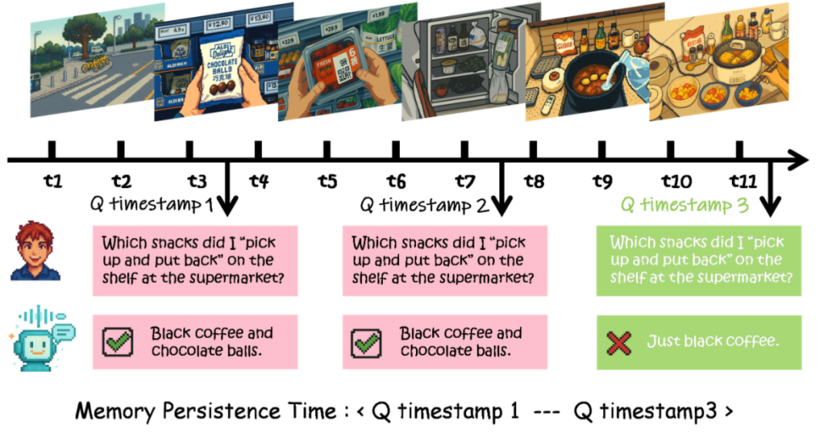
第二,记忆持续时间(MPT)。对“首次答对”的题目,在不重播原证据的前提下,按固定频率追问至首次失败,记录“还能记对多久”。此协议将正确性—时机控制—长时记忆合为一体评估。
在严格的流式评测与证据合规前提下,TeleEgo 展示出非常清晰的规律,即专有多模态助手整体表现更好,但优势主要集中在理解维度,而一旦任务需要细粒度的时间对齐与跨模态归因,表现会明显下滑。这说明当前系统更依赖“语义直觉”,但在对时间戳的对齐与具体实例的落地上仍显脆弱。
此外,开源且原生流式模型虽然参数更小,但通过更好的时序状态管理与发生控制,在实时准确率方面能缩小与专有系统的差距。反之,只有听看说全模态但缺少流式机制的模型,在线表现并不一定更好。延迟处理、缓存调度与对齐逻辑成了决定在线准确率的真正关键,而不只是“模态越多越好“。
从记忆持续时间来看,差异则更直观。专有模型在偏“理解”的任务上能记得更久,但面对“记忆类”细分任务,多数只能维持 2-3 分钟,开源模型整体更短。这表明模型确实能把长经历压缩成抽象语义,却难以长期保留那些可审计、带时间锚点的证据与不断变化的实体状态。
在 5 秒决策窗与证据不重叠的统一规则下,RTA 与 MPT 的分离提示两条清晰的优化路径。首先是“时间契约”式学习,让模型在时间戳条件下解码,学会该说时说、不该说时保持恰当沉默。其次是结构化长时记忆,用按时钟索引的事件键配合多模态锚定,既能记得久,也能拿得出证据。
总结来说,TeleEgo 把“说得对(正确性)”、“看得准(真实对齐)”、“说得时(时机控制)”绑在同一把标尺上,真正把第一视角助手的瓶颈,从“上下文越长越好”,推动到“可验证的对齐与实时的时序控制”。这为下一代 AI 助手提供了更明确、可落地的改进方向,让技术从“演示好看”,走向“日常好用”。
TeleEgo 填补了传统评测的核心缺陷,完善了第一人称 AI 助手的评估生态。它重新定义“多维度能力评估标准”,让 AI 技术的研发明确优化方向,为第一人称 AI 助手的“真实场景适配”提供测试依据,加速推动实用化落地。其应用价值覆盖从 AI 眼镜等可穿戴设备,到办公与学习、社交与交互、文化与商业等多种场景。
它能在多源噪声、多方对话与快速场景切换中检验“边看边听边答”的稳健性与时机控制。在演示、会议、编码与学习等流程中评估过程跟踪与跨段记忆;在排队、点单、多人互动等情境里衡量发言时机与礼仪、意图理解;在博物馆与出行等复杂公共环境下验证遮挡、噪声与陌生场景中的鲁棒性与跨时叙事构建。
面向未来,依托 TeleAI 正在重点布局和研发的智传网(AI Flow),以智能眼镜、智能手表为代表的智能可穿戴终端设备将具备更强的能力和更广的应用场景。而 TeleEgo 则为部署在“端-边-云”不同层级网络架构的家族式 AI 助手同源模型提供能力标准与优化依据,推动第一人称 AI 助手的实用化落地,让 AI 真正具备“像人一样感知、记忆、推理”的能力,为人类带来与外部世界交互的全新范式。
欢迎大家从 Github 或 HuggingFace 下载 TeleEgo 数据集,并将多模态大模型评测结果提交到 Project 主页的在线榜单。
Project 主页:https://teleai-uagi.github.io/TeleEgo
GitHub:https://github.com/TeleAI-UAGI/TeleEgo
HuggingFace:https://huggingface.co/datasets/David0219/TeleEgo
