



热门搜索
- 超多方言实时语音识别
- AIGC
- 语义大模型
- 智能体平台


 新闻详情
新闻详情CVPR 2026 | Xingchen AGI 破解T2I训练低效难题:CGPO精准投喂,效率与效果双提升
星辰通用人工智能实验室
星辰通用人工智能实验室(Xingchen AGI Lab)是中国电信星辰基础大模型的研发单位,将“基于国产芯片训练国际一流模型”作为自己的使命目标,开展战略性、引领性、系统性的通用人工智能全栈技术研发,推动国产生态成为通用人工智能原始创新和规模应用的重要力量。实验室于2026年3月在北京成立,历经前身近五年建设,团队成员超230人,平均年龄31岁,技术方向牵头人及骨干均毕业于清华、中科院、斯坦福、哥伦比亚等国内外知名高校,核心基模研发团队90%来自阿里、腾讯、百度等互联网大厂。当前,实验室基于中国电信国产万卡集群,已完成视觉、语音、语义和多模态四大方向布局,模型参数覆盖十亿/百亿/千亿/万亿,在GitHub、huggingface等主流开源社区下载次数突破60万,入选2025年“央企十大国之重器”。
在强化学习(RL)大幅提升文生图质量的今天,模型生成的图片越来越逼真,但训练效率一直是个老大难问题。主流做法是“均匀采样”,也就是随机抽题目来练,完全不管每道题对模型当下的学习到底有多大帮助。结果就是大量训练步数被浪费在“已经会了”或“完全不会”的题目上。
怎样才能让模型在每一轮训练中优先关注那些具有较高学习价值的样本?星辰通用人工智能实验室提出CGPO(Curriculum Group Policy Optimization),一种“自适应私人教练”式训练方法。它用同一提示词生成多张图的奖励方差来判断模型掌握程度:分数波动越大,说明模型越不稳定、越需要练习。CGPO 会优先安排这类“半会不熟”的题目,并自动平衡计数、辨色、位置等不同考点。
CGPO 在 GenEval、T2I-CompBench++、DPG Bench 等权威榜单上进入第一梯队,并在部分基准上超过 GPT-4o、DALL-E 3 等知名模型。
近日,该成果已入选CVPR 2026。论文从实时难度感知和动态课程的角度,系统地分析并缓解了强化学习训练中低效采样和类别失衡的问题。
随机抽题,让模型做了太多“无用功”
在分析主流文生图 RL 训练时,我们发现一个常见问题:训练时随机抽取提示词,好像每个题目机会均等,但学习收益却两极分化。模型早就熟练掌握的简单题目被反复训练,贡献不了新进步;远超当前能力的难题又总是全错,梯度信号几乎为零。
换句话说,模型练得满头大汗,却始终没练到“最该练”的题目。训练曲线看着平稳上升,实际上真正的有效训练量远低于预期。
这让我们开始反思一个默认假设:文生图训练真的只需要像发牌一样轮流练所有题吗?如果不是,那怎样才能让模型总在“最能进步”的题上反复磨炼?
训练效率低,问题出在“怎么出题”
现在的文生图 强化学习 训练普遍是“随机抽题 + 统一训练”,完全不考虑不同题目在当前模型水平下的“含金量”。模型可能相当多的时间都在“已会”和“学不会”的题目之间空转,无法主动聚焦到那些“正在学会边缘”的高价值样本上。
此外,文生图评测通常包含多个维度(比如颜色、计数、空间关系),不同维度天然难易不同。均匀抽题会导致模型在容易拿分的维度上反复刷分,弱势维度却长期得不到充分训练,最终就长成了“偏科生”。
最根本的原因是,传统抽题策略只关心数据分布的静态平衡,忽略了模型能力动态变化时,样本的学习价值也会跟着变化。这两者之间存在一条用固定策略无法填补的鸿沟。
这让我们确信:提升训练效率的一个重要切入点,不是去改模型结构,而是从源头重构抽题策略和课程安排。
CGPO:用得分波动找到该学什么
针对以上问题,CGPO设计了一个四步循环,旨在让模型持续聚焦于当前最具学习价值的样本,同时兼顾不同任务维度之间的平衡。
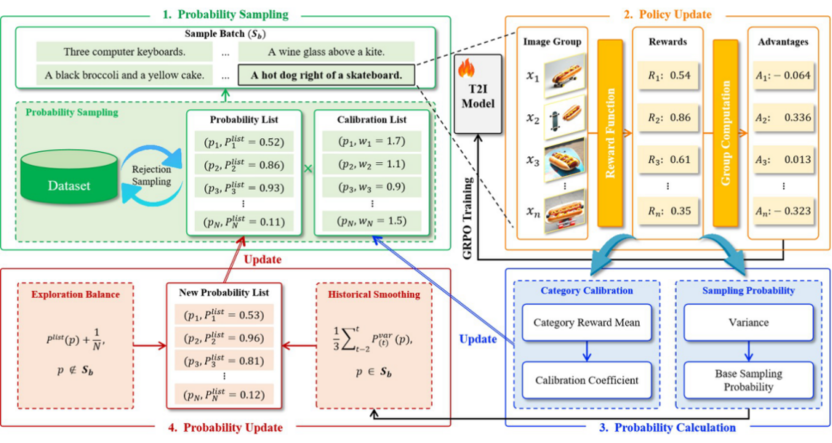
阶段一:
四步法,让教练动态识别“最该练的题”
1.按权重抽题:维护一个题目列表,每道题都有一个“被抽中概率”。概率高的题目更容易被抽到,但不会完全堵死其他题的路(采用伯努利采样的独立判断方式,避免相互挤压)。
2.生成图片、更新模型:对抽到的一批题目,每道题生成一组多张图,然后依据“组内比较”计算优势,去更新模型参数(这一步和 GRPO 的基础步骤一致)。
3.计算“得分波动”:对每道题生成的那组图的得分,算一下它们之间的差异程度(方差)。如果几张图得分差别大,说明模型在这道题上还不稳定、有提高空间——这正好是当前最值得练的信号。
4.更新抽题概率:根据波动程度,把高波动的题目被抽中的概率调高。同时,对那些一段时间没被抽中的题目,概率会小步自动增加,防止它们永远被遗忘。这样既能重点突击薄弱点,又保留了全局探索。
阶段二:
自动平衡各考点,不让模型“偏科”
训练时,CGPO 会同时关注多个评价维度(如颜色、纹理、数量等),定期统计各维度的当前平均得分。如果某个维度总是得分偏低,就通过一个比例公平的数学方法,自动调高这个维度相关题目的被抽中概率。这个调整力度可以平滑控制,从“完全公平分配”到“全力死磕弱点”之间自由过渡。这样一来,模型就没有“弱势学科”可以逃避,整体能力更均衡。
实验结果
一、主流评测基准的全面领先
CGPO 在 GenEval、T2I-CompBench++ 和 DPG Bench 三大主流评测基准上与现有方法进行了系统对比。实验基座采用 SD3.5-Medium,并以 Flow-GRPO 作为核心训练框架进行复现对比。在 GenEval 基准上,CGPO 不仅训练更快,整体得分和各项能力表现也都领先。
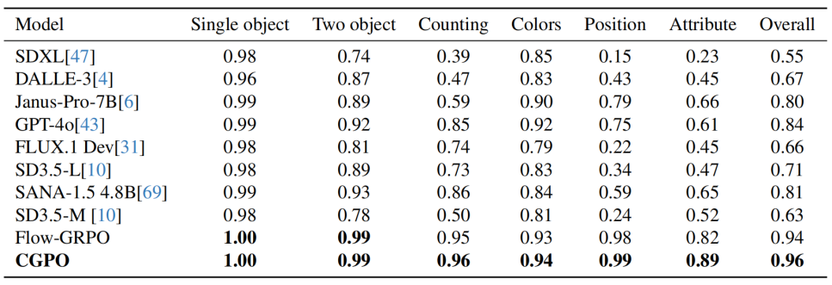
从 GenEval 的详细评分可以看出,所有模型在“单个物体”等简单任务上差距较小,而在“属性绑定”“位置关系”“计数”等复杂组合任务上差异显著。基座模型 SD3.5-M 在这些任务上表现较弱,而 CGPO 在各项复杂任务上均取得明显提升。例如,在“属性绑定”任务上,CGPO 相比 Flow-GRPO 提升约 7个点(从 0.82 提升至 0.89),并在“位置”和“计数”等任务上取得最优表现,最终达到 0.96 的整体得分,在当前对比方法中表现最佳。
二、训练效率显著提升
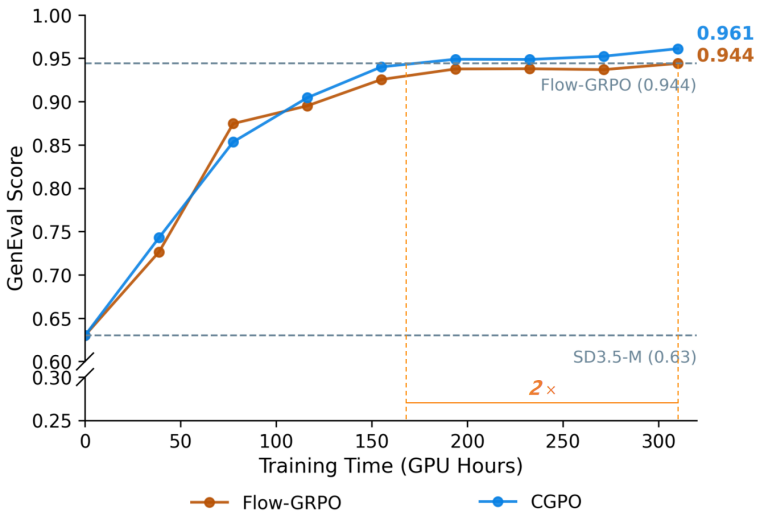
在训练效率方面,CGPO 在达到相同性能水平时显著减少了训练时间。训练曲线表明,从整体趋势来看,CGPO 的性能提升速度更快,在大多数训练阶段优于对比方法。这一现象与其优先采样高学习价值样本的策略密切相关,有效减少了无效训练带来的计算开销。
三、动态自适应学习
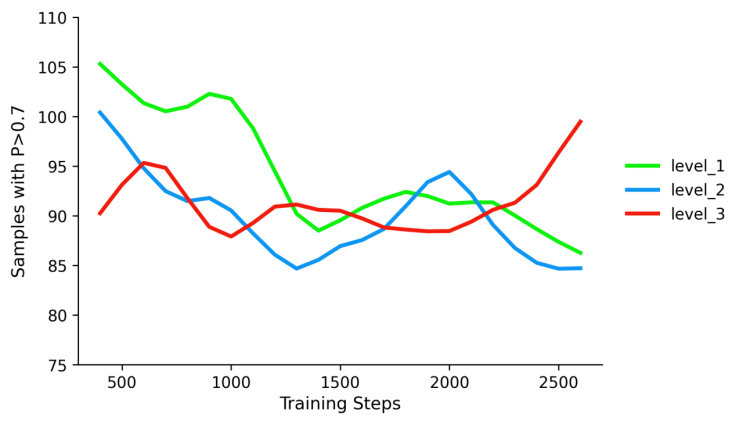
为进一步分析其课程学习机制,我们将提示词按照目标数量划分为不同难度级别,并跟踪训练过程中高概率样本的分布变化。结果表明,在训练初期,高概率样本主要集中在低难度任务;随着训练推进,采样逐渐向中高难度迁移。这一动态过程说明 CGPO 能够自适应地调整训练重点,使模型持续聚焦于当前最具学习价值的样本。
结 语
回到最初的问题:为什么文生图训练“狂练一整天,有效提升却有限”?CGPO 给出的答案很明确:传统方法只求“所有题都练到”,却无视了不同样本在不同阶段的学习价值的差别。当我们用“组图得分波动”当指针,用“动态概率采样”和“类别均衡”代替盲目海抽,就等于给模型装了一套“感知差异→动态聚焦→平衡优化”的导航系统,让它在最有价值的区间高效成长。
这项研究表明,在文生图逐步走向复杂组合与多维对齐的过程中,合理的训练策略能够显著提升学习效率。相比单纯增加训练规模,如何更有效地利用训练数据同样关键。CGPO 提供了一种基于自适应课程的可行思路,也为类似方法在更多多模态生成任务中的应用提供了参考。
主要作者介绍

星辰大模型全尺寸开源地址:
星辰语义基础大模型TeleChat已开源1B、3B、7B、12B、35B、36B、39B(MoE)、52B、105B(MoE)、115B的不同参数模型的训练和推理代码,链接如下:
https://github.com/Tele-AIhttps://huggingface.co/Tele-AI
https://modelscope.cn/organization/TeleAIhttps://modelers.cn/user/TeleAI