



热门搜索
- 超多方言实时语音识别
- AIGC
- 语义大模型
- 智能体平台


 新闻详情
新闻详情兼顾效率与性能:TeleAI 开源首个 MoE 架构模型
在医学科室分类出现以前,人们怎么看病?
大部分患者都需要排队等候“全科”医生,无论大病小病只能使用同一套诊疗流程,医疗资源浪费严重。
而在现代综合医院中,分诊台会先对患者症状作初步归因,再将患者引导至特定科室。随后专科医生做针对性诊断,诊疗水平和效率都大幅提升。

这一进化路径在大模型领域同样适用。传统稠密模型如同"全科医生",懂得多,但可能忙不过来。而 MoE(混合专家)模型则如同现代化医院科室体系,可以动态分配算力资源,根据任务需求去调用对应的专家模块,兼顾高性能和计算效率。因此,MoE 架构已成为大模型领域的主流技术方向。
然而,当前主流 MoE 模型普遍跃升到了千亿参数级别,将中小型项目的部署成本推高至难以承受的范围。如何在维持模型高性能与计算效率的前提下,实现低部署门槛的突破,已成为推动 MoE 模型普惠化必须攻克的关卡。
近日,在中国电信集团 CTO、首席科学家、中国电信人工智能研究院(TeleAI)院长李学龙教授的带领下,TeleAI 科研团队研发并开源了首个 MoE 架构的星辰语义大模型 TeleChat2-39B-A12B。该模型采用 16 路由专家架构,每次推理激活 4 个专家模块,总参数量为 39B,在推理过程中实际激活参数仅为12B,性能接近 35B 模型。
自发布以来,TeleAI 就陆续开源了其原创打造的 TeleChat 系列模型,包括 TeleChat-1B、7B、12B、52B 和 TeleChat2-3B、7B、35B、115B,均采用传统稠密参数架构,构建了全尺寸大模型开源布局。此次开源的 MoE架构 TeleChat2-39B-A12B 兼顾效率与性能,通过动态参数激活机制,在推理过程中无需调用全量参数,让专家模块“专事专用”,显著降低算力消耗。
训练方式创新
国产算力优化
在训练过程中,TeleChat2-39B-A12B 采用了创新的课程学习策略。
首先,在基础阶段聚焦低难度、高质量教育知识以及多语言数据,让模型在训练中获得较好的初始性能。
其次,在强化阶段为模型引入复杂数据,增大数学、逻辑推理、代码等数据占比,从而提升模型逻辑推理能力。
最后,在优化阶段使用高质量数据进行退火,持续提升模型效果。
通过一系列技术创新,该模型实现了国产算力优化与效能提升。
并行优化:
将 MoE 模块的 Tensor 并行域转换成专家并行域,使 AllToAll 通讯约束在节点内,降低跨节点通信开销,提高通讯效率。
流水线设计:
把 MoE 输入切成多个副本依次下发,将 Dispatch 通信、FFN 计算、Combine 通信三个环节连成流水线,实现 MoE 的计算通信掩盖。
负载均衡:
基于对内存和计算的开销建模,理论推导在内存约束下性能最优的流水线并行的负载配置,实现流水线负载均衡。
模型实力得到验证
持续贡献开源智慧
在通过综合评测数据集验证模型能力的过程中,TeleChat2-39B-A12B 仅凭借 12B 的激活参数量,就实现了与 TeleChat2-35B 接近的模型效果。
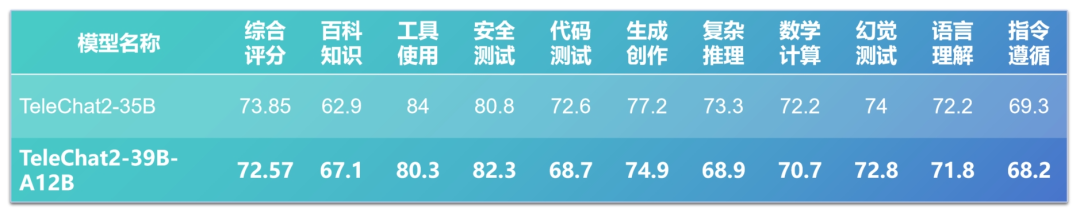

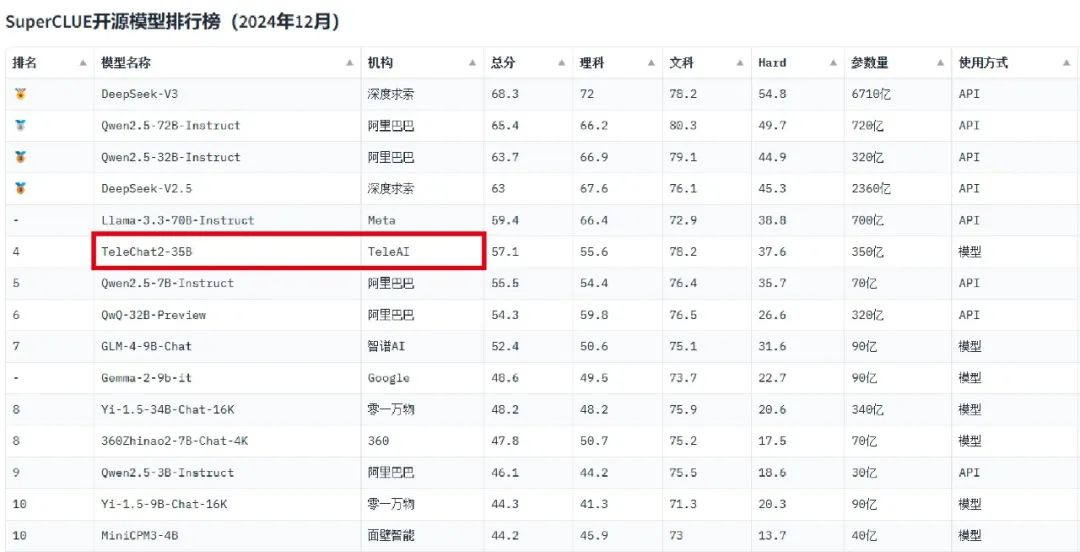
需要强调的是,作为对比基准的 TeleChat2-35B 模型本身已经实力不俗,在2024年12月的 SuperCLUE 开源模型评测中综合表现位列前三,仅次于通义千问与DeepSeek。这一对比结果也印证了 MoE 技术路线的有效性。
MoE 架构通过"动态专家调用+稀疏化计算"的核心突破,既保持了稠密模型的推理深度,又显著降低了算力消耗,这种"高精度与高效率"的平衡特性,为人工智能的规模化落地提供了关键技术路径。
此前,TeleChat 系列语义大模型已连续斩获中国科协“优秀开源应用项目”、Gitee“年度 GVP 最有价值开源项目”等权威奖项,并成为信通院2024年首批通过可信开源大模型成熟度认证的唯一单位,入选信通院2024年央国企开源项目典型案例。
TeleAI 将继续深耕 MoE 架构创新,并持续为开源生态建设贡献力量。
Github 开源地址如下,欢迎广大开发者使用:
https://github.com/Tele-AI/TeleChat2