



热门搜索
- 超多方言实时语音识别
- AIGC
- 语义大模型
- 智能体平台


 新闻详情
新闻详情WAIC 2025 | 入选 SAIL 奖 TOP30,TeleAI 国产大模型深度解析(第2弹)
近日,中国电信人工智能研究院(TeleAI)的“全国产大模型关键技术研发及规模应用”项目成功入选 WAIC 2025“卓越人工智能引领者奖(SAIL)”TOP30 榜单。
榜单链接:https://mp.weixin.qq.com/s/BxFPwW8J0xEecNAartYdEg
作为最早布局大模型的央企机构,TeleAI 构建了国内首个全模态、全尺寸、全国产的“三全”星辰大模型体系,由中国电信集团 CTO、首席科学家、中国电信人工智能研究院(TeleAI)院长李学龙教授牵头任总师,带领团队创新打造。
针对国产化大模型训练的难点和挑战,TeleAI 成功攻克了全国产化精度对齐、万卡集群训练性能优化等关键技术难题,进一步验证了基于 Ascend+MindSpore 的全国产架构(国产算力+国产训练框架),能够高效训练得到行业一流的语义基础大模型。
此前,已详细介绍团队在跨软硬件迁移精度对齐和并行策略变更精度对齐方面的创新实践,本篇将围绕国产化训练中的性能优化和经典问题进一步深度解析。

链接:https://mp.weixin.qq.com/s/SGpvGikFxoPFEoxR3sNeUQ
国产化训练性能优化
TeleChat2 系列模型的分布式并行训练采用基于 MindSpore 提供的大模型通用并行框架 4D 并行策略。
其中,DP(Data Parallel)数据并行沿数据的 Batch 维度切分,不同设备组计算不同数据 Batch 并在反向计算时同步梯度。
TP(Tensor Paralle)张量并行切分模型权重,计算中通过集合通信聚合激活值。
PP(Pipeline Parallel)流水并行将模型按层分为不同 Stage,不同设备组计算不同 Stage。
CP(Context Parallel)序列并行则把输入序列分割成多个片段,各片段在不同设备计算,让大模型突破单个设备内存限制,处理更长序列。
除基础并行策略外,TeleChat2 还应用 MindSpore 提供的选择重计算特性、进行整图计算通信掩盖的细粒度多副本特性,以及结合 VPP(Virtual Pipeline Parallelism)的 1F1B 调度和流水负载均衡调整的流水并行优化。对于超长序列场景,MindSpore 也具备 RingAttention 能力。
1.并行策略调优
为了测试最优的分布式并行策略参数,TeleAI 尝试了多组参数组合,TP 并行会引入 All-Gather/ReduceScatter 的通信;PP 并行会引入 Bubble 和 Send/Recv 通信,通过均衡等方式,减少 PP 并行的 Bubble,开启 PP 并行的效率要优于 TP 并行。
通过仔细调整并行度配置、硬件和软件,团队实现了下图(表1)中配置的模型算力利用率(MFU)。TeleChat2-115B 使用 8k 序列长度数据进行训练,在 512 卡上的配置达到 MFU 36.3%。
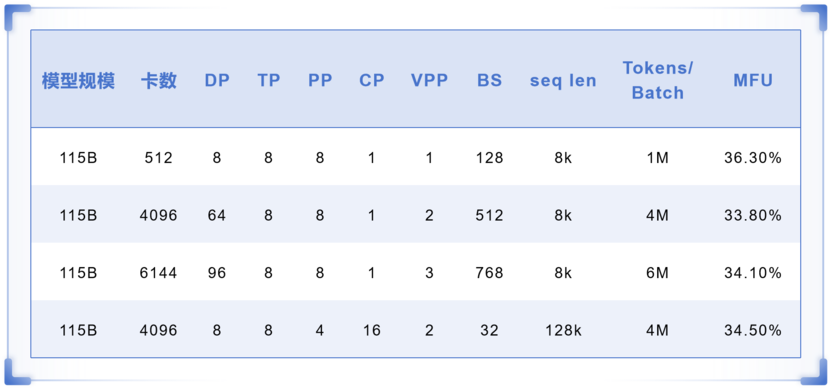
表1:TeleChat2-115B 训练性能与分布式并行配置
众所周知,大模型训练需要控制 Global Batch Size 不能过大,否则会影响最终的训练效果,在训练的起步阶段,一般控制在 4M Tokens 到 8M Tokens。因此在 4096 卡集群上训练 TeleChat2-115B 时,因为 DP 维度的扩大,导致 Tokens/Batch 的增加。
然而,当控制 Tokens/Batch 为 4M 时,Pipeline 的 Micro Batch 数下降,会导致流水并行的 Bubble 增加,因此团队利用 VPP 特性来降低Bubble,最终 MFU 为 33.8%。
当切换为 6K 集群进行训练时,将 VPP 的数目增加到 3,来一步压低 Bubble 占比,提升 MFU 到 34.1%。
在使用 128k 长序列数据集训练 115B 模型时,通过开启 CP 序列并行,来降低长序列带来的内存和计算压力,最终在 4K 集群上达成实训 MFU 34.5%。
2.流水并行优化
在流水线并行的训练场景中,内存分布的不均衡性尤为突出,尤其是前端 Stage 往往面临较大的内存压力。针对这一挑战,TeleAI 采取了调整不同 Stage 上的 Layer 数结合差异化的重计算策略。
在内存压力较大的 Stage,团队减少上面放置的 Layer 数目,且选择对全部层进行选择重计算,以最大限度地释放内存空间。而在内存压力较小的 Stage,则增加 Layer 数目,且进行部分层的选择重计算,以平衡计算开销与内存节省。
为了保证模型训练的效果,通常会限制训练的 Tokens 数,比如 8M、16M。当使用大集群进行训练的时候,因为 DP 数很大,会使得Micro_Batch 数变小。根据公式,在 Pipeline Stage 数不变的情况下,Micro_Batch 数变小会增大训练的 Bubble,导致性能下降。
为了提升流水线并行效率,减少 Bubble 的占比,MindSpore 提供了虚拟流水并行(Virtual Pipeline Parallelism,简称 VPP)调度方式。
传统的流水线并行通常会在一个 Stage 上放置几个连续的模型层(如 Transformer 层)。而在 VPP 调度中,每个 Stage 会对非连续的模型层进行交错式的计算,以更多的通信量来进一步降低 Bubble 的占比,如下图所示。
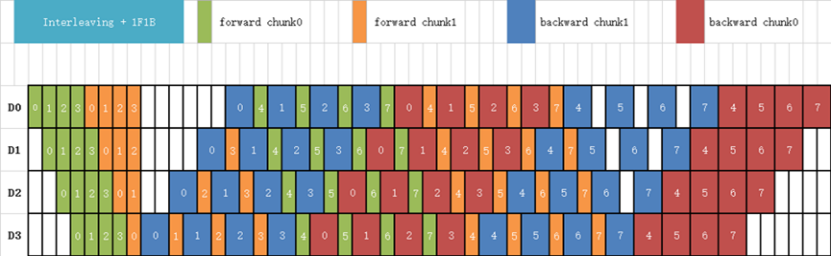
例如,传统流水线并行每个 Stage 有 2 个模型层,即 Stage0 有第 0-1 层,Stage1 有第 2-3 层,Stage2 有第 4-5层,Stage3 有第 6-7 层。
在 VPP 中,Stage0 有第 0 层和第 4 层,Stage1 有第 1 层和第 5 层,Stage2 有第 2 层和第 6 层,Stage3 有第 3 层和第 7 层。
3.细粒度多副本技术优化 TP 通信
大模型训练中,TP 引入的通信是一个显著的性能瓶颈,从网络算法角度来看,由于该部分通信域计算是有数据依赖,这一部分通信无法与计算进行掩盖。
为了解决这个问题,MindSpore 提出了多副本并行,即在一张卡内将网络拆分为两个分支,两个分支的计算与通信进行并发执行,如下图所示。

对网络进行拆分,最简单的方式是通过在 Batch 维度的拆分,类似于梯度累加的思路将多个分支的结果进行累加。但是该种方式要求单卡上的 BatchSize 至少为 2,在模型越来越大,显存越来越不足的情况下,实际运行的模型为了尽可能的提高显存的利用率,降低 Recompute,往往都是选择单卡上 BatchSize 为 1 方案进行模型训练。
为了解决这个问题,细粒度多副本针对 Sequence 维度进行多副本的拆分,并且做执行序的调整,实现计算与通信的最高效率并发。
4.长序列负载均衡
为了支持 128K 长序列训练,团队采用序列并行(Context Parallel),将 QKV 的序列维度切开,来节省显存占用。
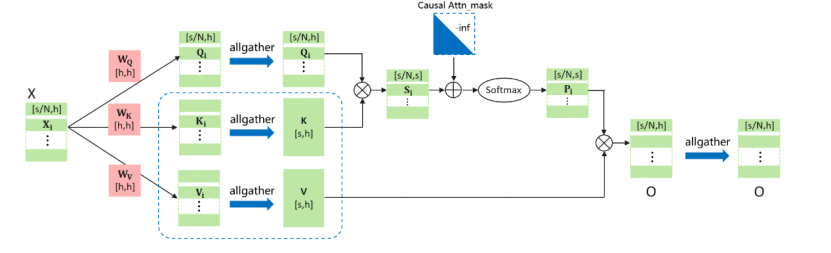
在 Attention 计算部分,通过 Allgather 通信将 KV 的序列维度拼接起来。同时为了实现序列负载均衡,团队通过点对点 Allgather 通信交换不同设备上 Query 和 Attention 计算结果的序列维度数据,将靠后的计算负载高的序列和靠前的计算负载低的序列做交换,以此实现不同设备上计算负载的完全均衡。
在更长的序列(M级别)下,MindSpore 提供的 Ring-Attention 算法会在 Attention 计算部分避免将 KV 的序列维度拼接起来,每次分块计算 QKV 的局部数据,在保证数学等价的同时保障完全负载均衡与计算通信掩盖,以此在超长序列下进一步节省显存占用并提升性能。
5.选择性重计算
大模型训练时会将正向传播的激活值保存起来,待到反向计算时使用,因此会占用大量内存,在开启 PP 流水并行时,因为要累计不同 Micro 的激活值,因此对内存的压力会更大。
在训练 70B 以上的模型时,通常会使用将激活值不存储,等到反向计算时再重计算的方式,来降低内存压力。重计算的缺陷在于,会在反向计算时引入额外的计算,降低算力利用率,因此在训练 TeleChat2 时,应用了 MindSpore 提供的选择重计算的能力,对关键算子进行重计算,以平衡计算开销与内存节省。
具体而言,TeleAI 选取了 FFN(前馈神经网络)中的 Silu 和 Mul 算子,以及 RMSNorm(均方根归一化)中从 fp32 到 bf16 的 Cast 算子作为重计算对象。
这些算子的重计算不仅计算代价较低,而且能够显著减少激活内存的占用,从而在保证模型训练效率的同时,实现了内存资源的优化配置。
MindSpore 还提供了通信选择重计算的能力,结合优化器并行使用,达到类似 Zero3 的效果;另外还有按层进行重计算、选择重计算、通信选择重计算的能力,结合流水并行优化。
国产化训练经典问题解析
1.精度问题经典案例:Norm 异常排查
在大模型训练过程中,Norm(梯度范数) 反映了训练中梯度的大小变化。在训练后期,Norm 值通常会趋于相对稳定。实际工作中,界定 Norm 异常需注意以下两点:
·偶发尖峰不一定异常:单个 Norm 尖峰可能并非严重问题。经过梯度裁剪(Clip)处理后,其对整体训练的影响通常非常有限。
·频繁超阈需经验判断:对于 Norm 值频繁超过某一阈值的情况,业界尚无统一标准。应基于当前模型的历史训练数据进行经验性判断。
对于 TeleChat2-115B 模型,若训练时长超过 6 小时后,Norm 值仍频繁超过 100,即可界定为 Norm 异常。实际影响训练 Norm 值异常的问题有很多,常见如下:
·数据集问题:更换数据集后出现 Norm 异常,应重点检查数据集是否存在脏数据,可通过数据实验或反向解码进行排查。
·框架问题:若在框架版本更新、并行策略更换或新特性上线前后出现 Norm 异常,建议通过实验排查框架。尝试进行对比实验或小规模复现。
·算法问题:大模型训练后期,若 Loss 持平不降且 Norm 持续高位,可能源于模型算法架构问题,需算法专家介入审视。
·硬件问题:若排除以上疑点或相关组件均未变更,则可能为硬件故障。需进行硬件压测,在集群内同时执行单机多卡实验,运行小模型至少 8K 步,重点检查计算单元或机内通信。
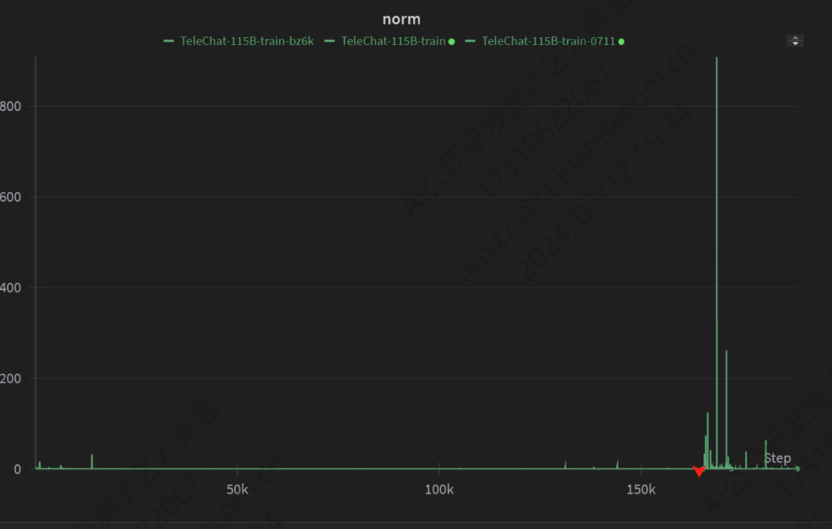
问题排查结果与改进措施:
·问题定位:经排查,上图问题在不同检查点(CKPT)和数据集下均可复现,故排除因素 1(数据集)和 2(框架)。优先考虑硬件问题,经大规模压测,发现某台机器存在硬件故障。
·解决方案:最终移除故障机器后,训练恢复正常。
·改进措施:新增计算精度测试,后续集群拉起时,将增加一轮 NPU 计算精度测试,确保全集群精度一致;增强日志记录,针对 Norm 异常情况,在 INFO 级别日志中额外记录每个数据并行(DP)组内的 Norm 值,便于缩小排查定位范围。
2.性能问题经典案例:Step-Time 异常的排查
模型训练速度是人工智能发展的核心引擎,直接决定了研发效率、创新迭代周期以及技术落地的可行性。更快的训练速度能带来多方面的显著优势。
·提升研发与创新效率:研究人员能在相同时间内探索更广泛的模型架构、超参数组合和训练技巧,极大提高实验效率并增加取得突破的可能性。
·降低研发成本与门槛:训练时间的缩短直接减少了昂贵的算力资源(GPU/NPU)占用和电力消耗,有效降低了研发成本,使更多参与者能够涉足该领域。
在实际训练过程中,Step-Time(单步训练时间) 作为反映训练速度的关键指标,是需要重点监控的。
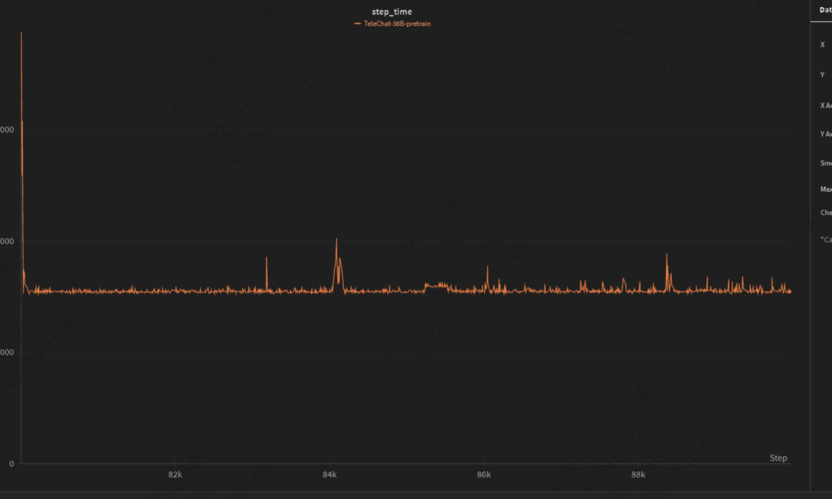
正常训练
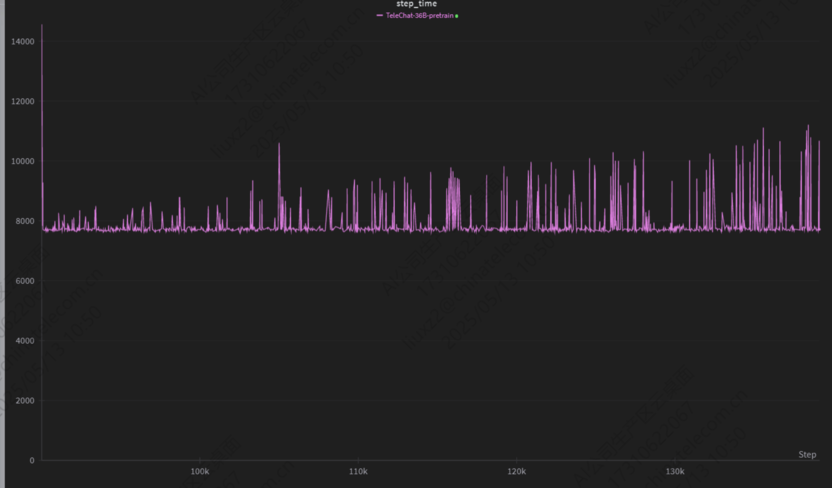
异常情况
从训练过程可以看出,单步训练时间呈喇叭状(逐渐)放大。针对此问题,定位思路主要有两种:
·特征分析法:该问题的典型特征是训练时间随步数增加而逐渐放大。有经验的开发者应优先考虑内存泄漏、缓存占用增长或慢查询(如查表操作效率下降)等常见原因。
·分步计时法:在正向查询流程中添加计时点(打点),记录每一步的耗时。通过观察耗时增长的关键步骤,缩小排查范围,进而精确定位具体原因。
问题排查结果与改进措施:
· 故障定位:经排查发现,由于实际运行环境与代码适配的驱动版本不匹配,导致哈希表(Hash表)不断增大,哈希冲突显著增多。这进而使得部分依赖缓存的查表操作效率下降,最终表现为训练时间逐步增加。
·故障特性:在部分版本驱动上存在该问题,部分驱动无法复现。
·解决方案:升级驱动到统一的配套版本后问题解决。
·改进措施:充分长稳验证,必须进行长时间稳定运行的充分测试验证;版本管理规范,应建立严格的版本管理体系;版本选择策略,尽量使用经过验证、问题较少的配套新代码进行训练。生产环境虽需保持稳定,但不应过度保守而拒绝必要的、经过验证的更新。
在本次 2025 世界人工智能大会期间,由中国电信人工智能研究院(TeleAI)、中电信人工智能科技(北京)有限公司、上海“模速空间”大模型创新生态社区主办的“TeleAI 科技前沿论坛”还将于 7 月 27 日在模速空间举办。
论坛将聚焦人工智能前沿理论突破与技术创新实践,邀请来自全球的 AI 领域顶尖专家、青年学者、新锐学子,及产业一线的企业家、开发者,交流创新趋势,碰撞前沿思想,共同探索科技前沿的应用与转化,旨在搭建一个国际化的学术交流与创新合作平台。

链接:https://mp.weixin.qq.com/s/kwv7Nwm6XCispRCqELdbiQ
点击“阅读原文”即刻报名预约,敬请关注!