



热门搜索
- 超多方言实时语音识别
- AIGC
- 语义大模型
- 智能体平台


 新闻详情
新闻详情ICCV 2025 | TeleAI 获具身智能运动控制及人脸反欺诈挑战赛双料冠军!
近日,计算机视觉国际大会(ICCV 2025)正式召开,中国电信人工智能研究院(TeleAI)具身智能和视觉理解研发团队分别在大会同期举办的“多地形人形机器人运动控制挑战赛”和“人脸反欺诈挑战赛”中,与来自全球的顶尖团队激烈角逐,并双双获得赛道冠军。

ICCV 是中国计算机学会(CCF)推荐的 A 类国际会议,与 CVPR、ECCV 并称为计算机视觉领域三大顶级会议。TeleAI 以“智传网(AI Flow)”为理论基础,在本次两项挑战赛中取得创新成绩,不仅是来自国际学术和产业各方的认可,更为前沿技术落地提供坚实基础。
冠军!
让机器人征服复杂地形
当前,人形机器人表演已经屡见不鲜,跳街舞、翻跟头、扭秧歌......已成为各大展会,甚至晚会的必要项目。然而,机器人的高难度动作通常在平坦的地方进行,一旦路面稍有崎岖就可能瞬间摔倒或抽搐,暴露出其运动控制策略在真实世界中的脆弱性。
为了解决这一痛点,让机器人可以在真实场景中具备更强的适应性和泛化能力,ICCV 2025 大会同期举办“多地形人形机器人运动控制挑战赛”,旨在推动人形机器人在楼梯、斜坡、崎岖路面等无规律复杂地形中实现稳定、可靠的自主行进能力。

挑战赛示例地形
TeleAI 具身智能团队设计了一套两阶段训练框架与自适应课程学习机制,不仅成功为宇树 H1-2、G1 及傅立叶 N1 三款主流人形机器人平台开发了通用控制策略,更在鲁棒性、极限性能和泛化能力三大核心评估维度上均表现卓越,一举夺得比赛冠军。
创新1:两阶段运动控制训练框架,从“学会走路”到“征服险路”。
第一阶段是为机器人的“筑基”阶段,即在平坦地形上进行预训练,让机器人掌握平衡、节律性步态和基础速度跟踪等核心运动技能。
第二阶段则是“进阶”阶段,将预训练好的策略迁移至包含楼梯、斜坡等多种复杂地形的环境中进行微调。同时,策略的输入中融入了周围地形的高度图信息,赋予机器人“看见”并理解脚下环境的能力。
有了扎实的基础和环境感知,机器人便能从容应对各种地形挑战。
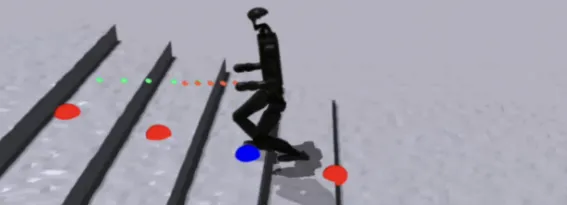
地形训练示意图
创新2:多地形自适应课程学习机制,让 AI 在“动态难度”中成长。
为了让模型不局限于特定场景,TeleAI 还设计了一套精妙的“AI 训练课程”。
首先,是动态难度调整。在训练环境中设置跑酷、跨栏、桥梁等多种地形,每种地形细分为 30 个难度等级。系统会根据机器人单次任务的表现(如行进距离)自动调整下一次任务的难度,成功则加难,失败则降难,确保机器人始终在“学习区”内高效成长。
其次,是防过拟合采样。为避免模型“死磕”最高难度而忽略基础,每次任务开始时,机器人有 50% 概率在当前难度训练,另有 50% 概率被“降级”到一个更低的难度上。这种机制强制模型在各种难度下都保持熟练,从而获得更强的整体鲁棒性和泛化能力。

动态难度地形
正是基于这套“组合拳”的训练,机器人在面对前所未见的混合地形时,依然能展现出惊人的适应性和稳定性。TeleAI 的解决方案在挑战赛设定的鲁棒性评估、极限评估、泛化评估三个维度中均表现出色,领先其他参赛团队。
面向未来,结合智传网(AI Flow)的强大智能传输能力,人形机器人可以代替人类进入复杂和极端的场景中进行抢险救灾、农林勘探、工业检修。TeleAI 的创新成果让“机器人真正融入人类生活”的终极目标再一次前进了坚实的一步。
冠军!
让人脸欺诈无计可施
随着人脸伪造技术的不断升级,伪造手段愈加逼真,对人脸识别系统的准确性和安全性提出了更高挑战。为了提升系统的可信度,人脸反欺诈(Face Anti-Spoofing,FAS)成为生物识别领域的核心课题之一。
然而,如何同时识别物理攻击与数字伪造仍是一大难题。前者(如打印、重放、3D 面具等)源自真实采集,而后者(如身份篡改、对抗样本与 AIGC 生成等)则以微妙的像素级改动实现欺骗。现有方法多将二者分开处理,通用检测模型的构建受到显著制约。
为填补这一空白,ICCV 2025 大会同期举办“人脸反欺诈挑战赛”,并设置“统一物理-数字攻击检测赛道”。TeleAI 凭借创新提出的“基于语义锚点实现统一的物理-数字攻击检测方法”获得赛道冠军。
本次竞赛主要考察两个核心方面。
首先,应对数据分布不均衡。在训练和验证数据中,由于正负样本比例区别较大,且不同攻击种类样本比例差异也较大,导致模型容易忽略某些长尾攻击类别。
其次,提升模型泛化能力。在训练和验证数据中,未提供 3D 面具攻击、ID 一致生成攻击等样本,对模型泛化能力要求极高。
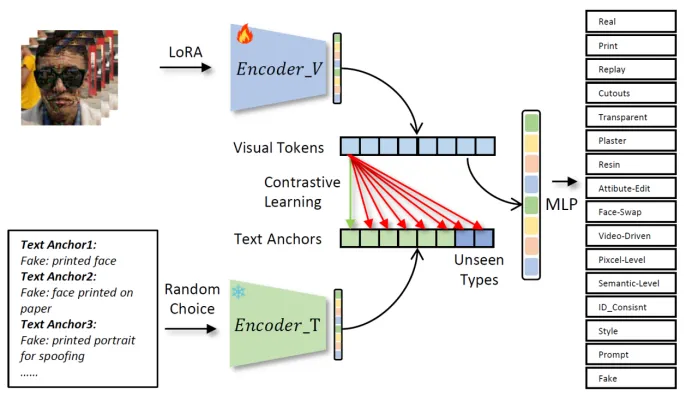
基于语义锚点的模型框架
TeleAI 团队设计了一个基于语义锚点的模型框架。该框架使用一个基于 LoRA 微调的 CLIP ViT 作为主干网络用于提取图像特征,同时为每种攻击设计不同的文本描述,并使用冻结的 CLIP 文本编码器提取语义特征作为语义锚点。
通过比对学习机制,模型将提取的图像特征与对应的语义锚点特征靠近,与其他类别的语义锚点特征远离,最终使用一个 MLP 分类器对图像特征进行分类,确定图像所属攻击类别或真实图像。
在训练过程中,团队还引入了权重均衡、文本描述优化以及随机锚点选取等策略。
权重均衡解决数据分布不均匀问题,有效提升模型在少量类别的性能,奠定基础能力。文本描述优化能带来更准确的语义锚点特征空间,是图像特征具备更优的可分性。随机锚点选取则有效扩增了每种类别的语义特征空间范围,在训练过程中起到重要作用。
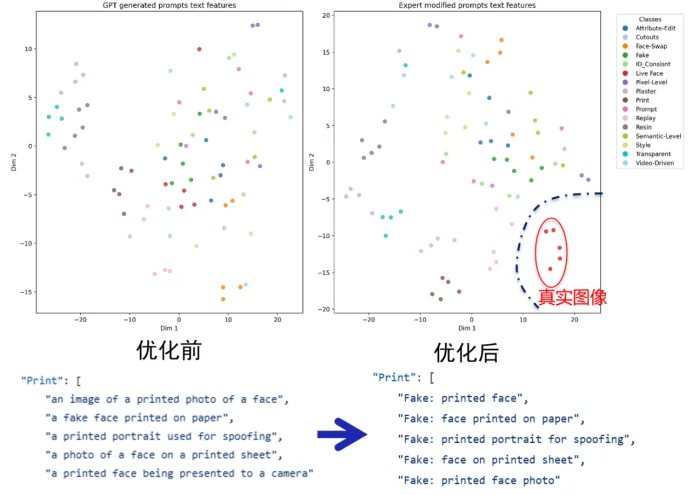
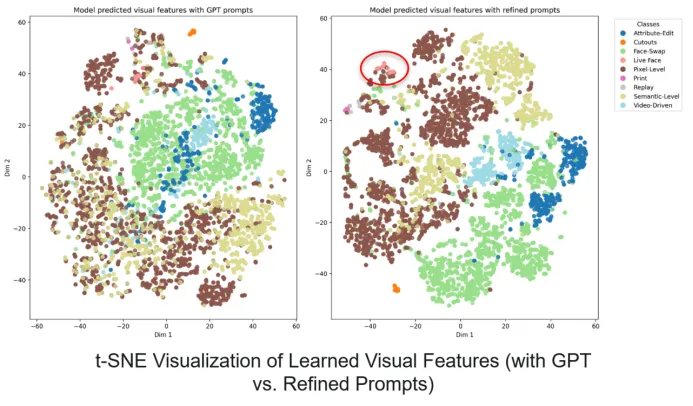
语义锚点特征空间以及经语义锚点对齐训练后的图像特征空间在优化后具有明显效果提升
在数据方面,TeleAI 团队对数据进行了详细分析和清洗,并使用训练数据,借助最新开源方法,生成了一批仿真数据,以弥补数据缺陷。实验证明,以上策略的组合有效提升了模型能力,最终在 AUC 评测指标中达到 99.99%,力压其他参赛团队。
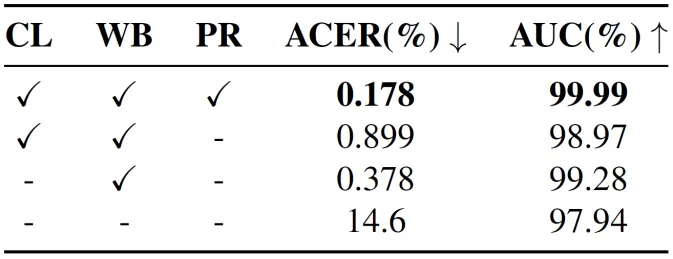
剥离实验
凭借在图像鉴伪领域的多年深耕经验,TeleAI 的解决方案在复杂多变的伪造场景中能保持卓越的鲁棒性和精确度。结合智传网(AI Flow)的“端-边-云”高效协同能力,此方案将应用于更广泛场景下的安全身份验证,为人工智能技术落地提供有利保障。