



热门搜索
- 超多方言实时语音识别
- AIGC
- 语义大模型
- 智能体平台


 新闻详情
新闻详情与时间赛跑守护方言:中国电信星辰语音大模型升级至支持50种方言自由混说
当来电号码说出“子阮子阮尼类”的时候,12345接线员面前的屏幕上立马出现了“谢谢你们”这四个字。“子阮子阮尼类”是一句温州话。接入大模型后,被誉为最难懂方言之一的温州话被成功“破解”。
在发布首个首个支持40种方言自由混说的语音识别大模型后,TeleAI近期再取得重大进展,将方言种类从40种升级至50种,并已在市政便民服务热线、智能会议记录、智慧教育及数字人等场景广泛落地应用,让沟通更加自然流畅,极大解决老年人及“老少边穷”地区人们的信息服务无法触达的问题,为人们搭建一条通往AI时代沟通的桥梁。
数据显示,中国约有20%的人口尚未普及普通话,面临信息服务难以触及的困境。在处理每天数万通客服热线时,老年和老少边穷地区人群存在‘一着急就说方言’或‘说不标准普通话’的问题。
随着TeleAI 星辰语音大模型的技术升级,让实时消除方言沟通隔阂成为可能。当然,让大模型掌握50多种方言并非易事。我国方言的语音识别难度大,即使是同一种方言,不同地区也存在差异。开发这样精确的方言大模型首要任务首先需要建立一个高质量的方言数据库,TeleAI已构建超50种,超50万小时的高质量方言数据库,方言数据库在丰富性和高质量等层面均居于业内前列。
为了让有限数量的方言数据发挥更高训练效能,研究团队首创“蒸馏+膨胀”联合训练算法,解决了超大规模、多场景数据集和大规模参数条件下预训练坍缩问题,实现80层模型稳定训练。通过“从语音到token再到文本”的建模新范式,大大降低推理时语音传输比特率。还采用了创新的“预训练+微调”策略,通过海量无标注数据进行预训练,再结合少量有标注数据进行微调,从而实现了高效且经济的模型训练。这一技术路径不仅大幅降低了对人工标注数据的依赖,还显著提升了模型的性能、稳定性和精准度
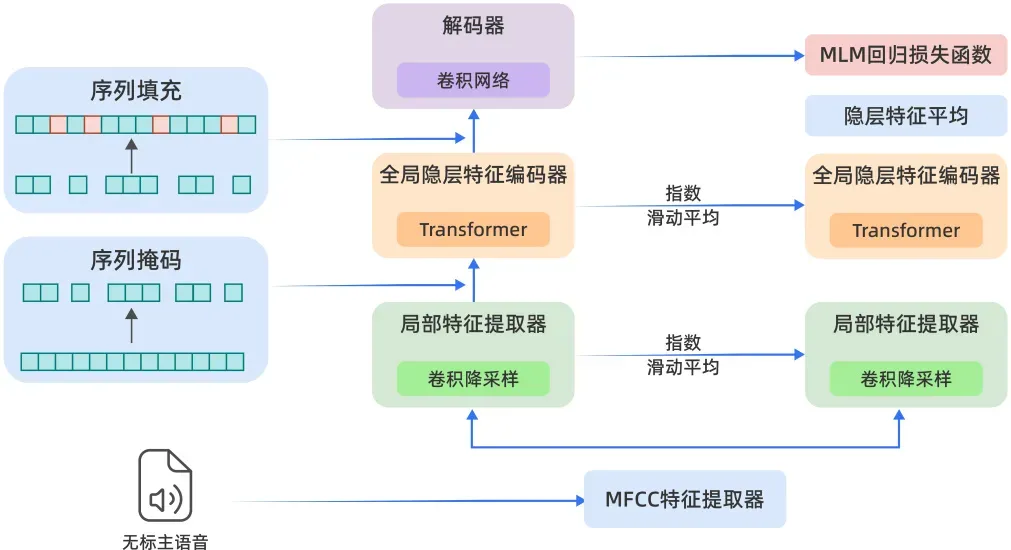
这一算法创新显著提升了语音识别的能力和精准度。多种方言在一个长句中混说,比如半句上海话后面连半句粤语,星辰语音大模型也能无压力识别。星辰语音大模型以绝对领先的性能,斩获多个国际权威赛事冠军。在权威国际语音顶会INTERSPEECH2024离散语音单元建模挑战赛上斩获语音识别赛道冠军。在业内知名的多方言语音识别数据集KeSpeech任务上,星辰语音大模型打破纪录,领先之前最优结果20%,以高达92.97%的字准确率刷新最优结果。
目前星辰语音大模型已在北京、福建、江西、广西、内蒙古等地的中国电信万号智能客服中试点应用,实现日均处理约200万通电话的服务力度。在教育领域,星辰语音大模型助力小学防霸凌项目,精准识别预警,其语音识别与合成技术赋能中国电信星辰教育智能体,接入多种教育终端,提升孩子交互体验。在智能会议场景,其超多方言识别能力已上线星辰慧记智能会议系统,日均处理语音超 700 分钟,助力企业快速转写并总结不同地域的客户声音,提升开会效率。
“大约平均两周就会有一种语言消亡。”来自联合国教科文组织的调查数据触目惊心:世界上现存约6700种语言,其中约40%的语言濒临消亡,我国25种方言使用者不足千人。
加速方言大模型研发是在与时间赛跑,超多方言语音识别大模型只是TeleAI规划设想中的第一步,接下来将持续拓展方言种类、提高识别精确度,争取早日覆盖全国333个地市和主要少数民族语言。
TeleAI已将语音识别大模型全面开源,希望联合更多开发者、专家、方言爱好者及大众用户共建覆盖更多方言的大模型,打破沟通壁垒,共同传承语言文化,推动人工智能普惠。
GitHub开源地址:
GitHub - Tele-AI/TeleSpeech-ASR