大模型体验中心
一站式体验由中国电信完全自主研发的星辰大模型及 AI 原生应用。

开发平台
为企业及开发者提供 AI 模型训练、应用开发等一站式工具与平台,降低开发门槛,加速AI应用落地。
应用产品
汇聚智能体应用、AI应用、大数据、软硬一体等标准化 AI 产品,覆盖多元场景,让 AI 能力从 “构想” 直连 “应用”
解决方案
以 “场景洞察 + 技术融合” 为锚,打造从需求诊断到价值落地的全链路方案,帮企业破解行业痛点,实现智能化转型 “精准突围”。
关于天翼AI
我们是中国电信旗下开展人工智能业务的科技型、能力型、平台型专业公司,致力于成为人工智能领域的国家战略科技力量。



热门搜索
- 超多方言实时语音识别
- AIGC
- 语义大模型
- 智能体平台


 收起侧栏
收起侧栏
创建与配置本地知识库
 最近更新时间: 2026-05-19 17:56:19
最近更新时间: 2026-05-19 17:56:191. 知识库创建
- 点击左侧导航栏中的知识库按钮进入知识库管理页面,点击创建知识库,单用户最多创建50个知识库。
- 支持用户针对已创建的知识库或创建知识库时添加标签,方便用户管理自己搭建的知识库。
- 文件上传指定的文件类型:TXT、MARKDOWN、PDF、OFD、XLSX、XLS、DOCX、DOC、CSV、WPS、WPT、ET、ETT、JPG、JPEG、PNG、BMP、TIFF
- 支持用户自定义标签(标签上限10个),并在创建知识库的时候选择标签。
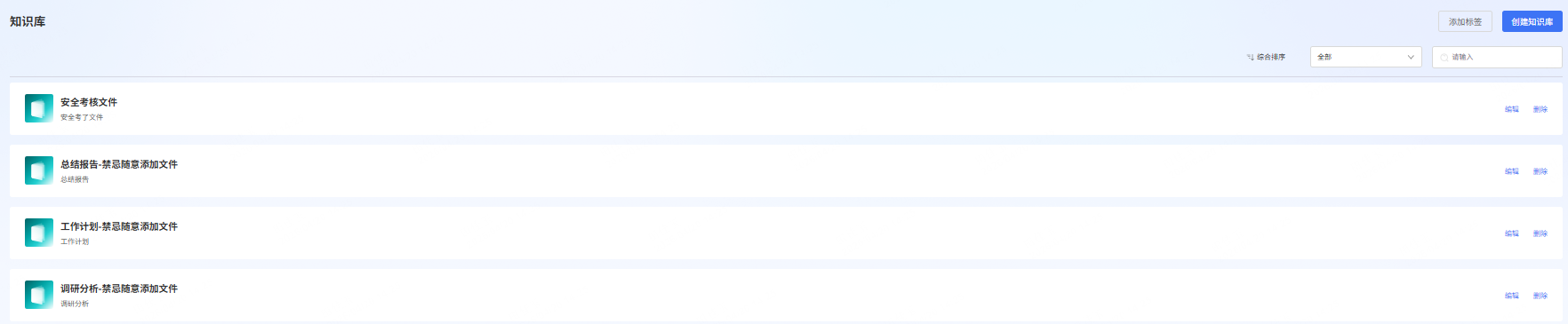
2. 数据类型及数据上传要求
平台支持三种数据类型文件,包含结构化数据、非结构化数据、多模态数据。
- 非结构化数据:支持上传文件格式包含TXT、MARKDOWN、PDF、DOC、DOCX、OFD、WPS、WPT格式。
- 结构化数据:支持上传文件格式包含CSV、XLSX、XLS、ET、ETT格式。
- 多模态数据:支持上传文件格式包含JPG、JPEG、PNG、BMP、TIFF格式
- 根据选择数据类型上传对应文件。上传非对应数据类型文件,会异常报错。
- 非结构化数据文件:要求上传的每个文件不超过50MB,最多同时上传30个文件
- 结构化数据文件:要求上传的每个文件不超过20MB,最多同时上传50个文件
- 多模态数据文件:要求上传的每个文件不超过5MB,最多同时上传50个文件
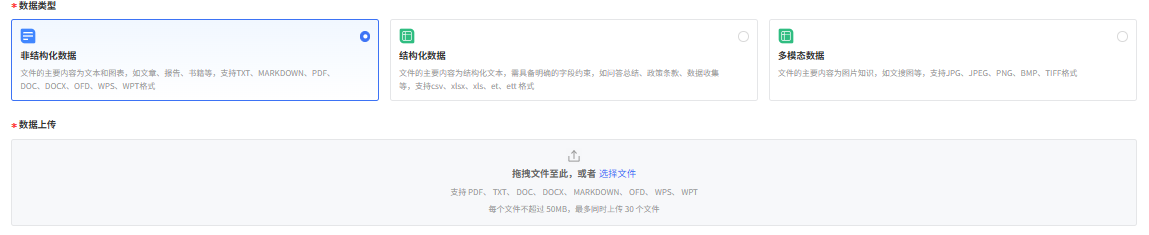
3. 配置选择
3.1 分段处理:适用于非结构化数据类型,文件格式包含TXT、MARKDOWN、PDF、DOC、DOCX、OFD、WPS、WPT。(结构化数据会按照表格行数进行切分;多模态数据无相关功能。)
3.1.1 自动分段与清洗方式:自动模式适合对分段规则与预处理规则尚不熟悉的初级用户。在该模式下,平台将为你自动分段与清洗内容文件,你不需要进行任何筛选与操作。
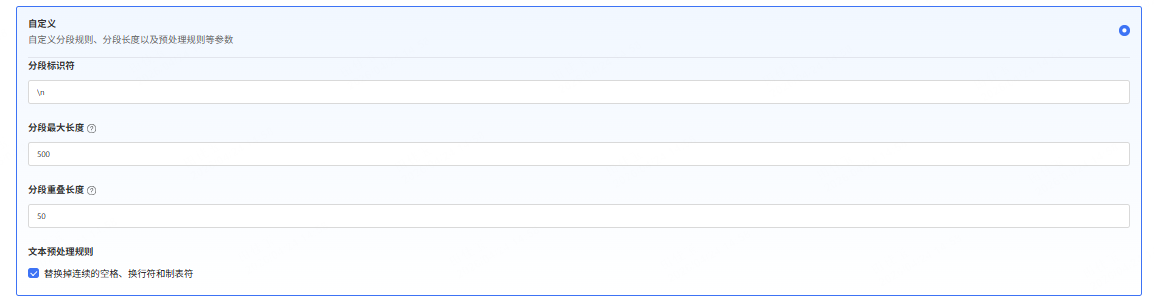
3.1.2 自定义:自定义模式适合对于文本处理有明确需求的进阶用户。在自定义模式下,你可以根据不同的文档格式和场景要求,手动配置文本的分段规则和清洗策略。配置参数如下:
- 分段标识符:系统将在文本中出现指定的标识符的分段,文本换行时将自动分段;
- 分段最大长度:根据分段的文本字符数最大上限来进行分段,超出该长度时将强制分段。一个分段的最大长度为500-10000字节;
- 分段重叠长度:分段重叠指的是在对数据进行分段时,段与段之间存在一定的重叠部分。这种重叠可以帮助提高信息的保留和分析的准确性,提升召回效果。建议设置为分段长度 Tokens 数的 10-25%。
- 文本预处理规则:文本预处理规则可以帮助过滤知识库内部分无意义的内容。例如替换连续的空格、换行符和制表符。
3.1.3 文档层级分段:该模式针对含标题层级的结构化文档(如手册、报告),系统自动识别标题级别,按嵌套关系切分为树状段落,保留父子隶属结构,适用于知识组织与导航构建,无需人工干预。
- 分段层级1-3,平台系统默认分段层级为1级。
- 注意:在该分段处理选择下,解析方式不支持选择精准解析。

3.2 Embedding模型设置:
- Embedding 模型用于将自然语言处理转为向量,用于后续检索和大模型处理。
- 可选择的内置embedding模型,或在设置-模型来源中添加第三方embedding模型。

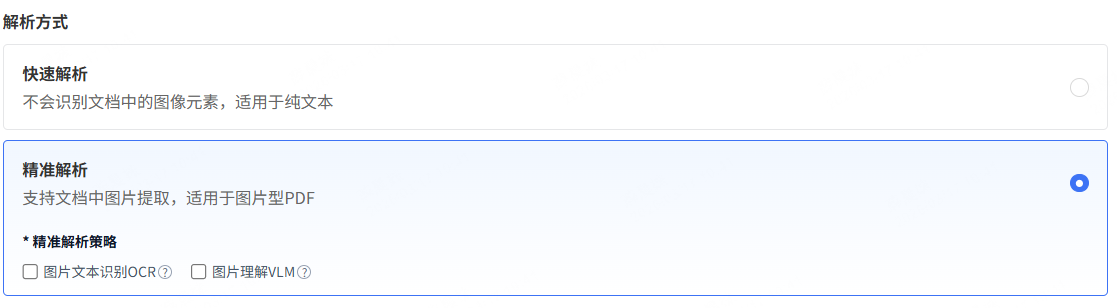
3.3 解析方式
解析方式包含快速解析和精准解析,适用于非结构化数据类型,支持文件格式包含PDF、TXT、DOCX、MARKDOWN格式。
- 快速解析:适用于纯文本类型,不会识别文档中的图像元素。
- 精准解析:适合于图片型pdf(例如文件的扫描件),包含ocr算法能力,能够支持文档中图片提取。
- 精准解析策略(可选,仅支持单选):
- 图片文本识别(OCR):识别图片中的文字,适用于文档扫描件等
- 图片理解(VLM):调用多模态大模型理解图片,适用于画面描述、图表研读等场景。
3.4 知识增强
知识增强里面包含问题生成、段落总结、知识图谱三种形式,适用于非结构化数据。知识增强的作用是辅助召回涉及知识库问答的内容。大模型会参与问题生成或段落总结的提取,在提取过程中会有一定的模型消耗。
- 段落总结:开启后,会自动生成1个知识点。
- 问题生成:开启后,会自动生成3个问答对。
- 知识图谱能力:开启知识图谱能力后,能够使用graphrag算法提取文档内容中的实体,形成图谱辅助召回。
