大模型体验中心
一站式体验由中国电信完全自主研发的星辰大模型及 AI 原生应用。

开发平台
为企业及开发者提供 AI 模型训练、应用开发等一站式工具与平台,降低开发门槛,加速AI应用落地。
应用产品
汇聚智能体应用、AI应用、大数据、软硬一体等标准化 AI 产品,覆盖多元场景,让 AI 能力从 “构想” 直连 “应用”
解决方案
以 “场景洞察 + 技术融合” 为锚,打造从需求诊断到价值落地的全链路方案,帮企业破解行业痛点,实现智能化转型 “精准突围”。
关于天翼AI
我们是中国电信旗下开展人工智能业务的科技型、能力型、平台型专业公司,致力于成为人工智能领域的国家战略科技力量。



热门搜索
- 超多方言实时语音识别
- AIGC
- 语义大模型
- 智能体平台


 收起侧栏
收起侧栏展开侧栏
音频文件转写
 最近更新时间: 2026-01-07 15:04:49
最近更新时间: 2026-01-07 15:04:49产品名称:音频文件转写
产品介绍:
基于端到端语音识别能力,将批量上传的音频文件转换成文本,适用于语音质检、会话内容分析等场景
主要功能:
话者分离 :当录音中有多个说话人时,可以区分不同说话人进行识别
智能优化 :根据语音内容,自动插入适当的标点符号,输出标准化文本形式,并能够对识别结果进行智能验证和修正,提高文本的可读性
字体选择 :能够生成简体和翻译的转写结果,支持用户根据场景进行选择
语义断句 :根据音频内容的语义和语调特征,将连续语音分段为完整句子,自动插入标点,使识别结果更符合自然语言表达
支持热词 :用户能够自定义上传的热词,通过优先匹配热词提升在相关领域的识别准确性
产品定价:
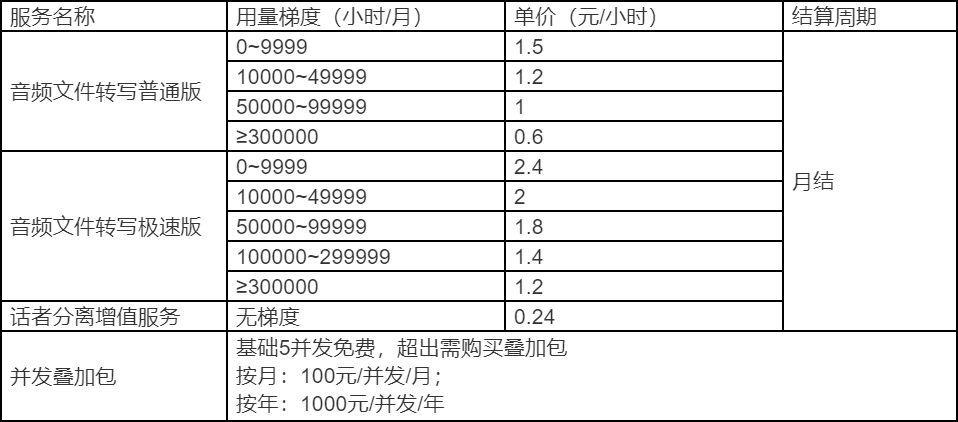
注:如返回网关错误码(见开发指南->公共常量->返回状态码),不做计费