大模型体验中心
一站式体验由中国电信完全自主研发的星辰大模型及 AI 原生应用。

开发平台
为企业及开发者提供 AI 模型训练、应用开发等一站式工具与平台,降低开发门槛,加速AI应用落地。
应用产品
汇聚智能体应用、AI应用、大数据、软硬一体等标准化 AI 产品,覆盖多元场景,让 AI 能力从 “构想” 直连 “应用”
解决方案
以 “场景洞察 + 技术融合” 为锚,打造从需求诊断到价值落地的全链路方案,帮企业破解行业痛点,实现智能化转型 “精准突围”。
关于天翼AI
我们是中国电信旗下开展人工智能业务的科技型、能力型、平台型专业公司,致力于成为人工智能领域的国家战略科技力量。



热门搜索
- 超多方言实时语音识别
- AIGC
- 语义大模型
- 智能体平台


 收起侧栏
收起侧栏
应用评测
 最近更新时间: 2026-05-20 09:35:38
最近更新时间: 2026-05-20 09:35:381. 概述
为帮助用户全面评估AI智能体的性能及使用质效,平台新增评测模块,当前支持对自主规划式智能体进行标准化测评。通过评测集及评测规则的自定义配置,用户可定量分析智能体的响应准确性、工具调用稳定性及知识覆盖度等关键指标,为优化决策提供数据支撑。
2. 评测流程
评测模块包含三个核心环节(评测集、评测规则、评测任务),确保评估过程的完整性和可追溯性。
2.1 评测集
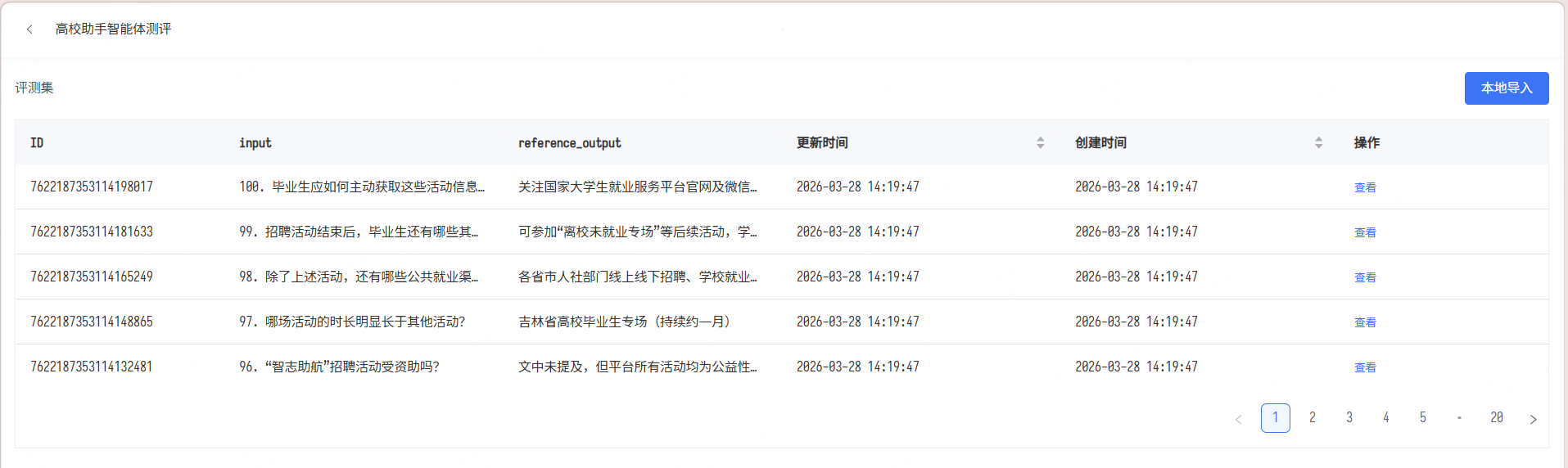
功能:通过特定提问或使用官方预制的标准数据集,构建用于测试智能体的部署集。评测集可导入外部文件(如Excel/CSV),或从平台现有知识库直接提取测试样本。
操作说明:
- 点击“创建评测集”
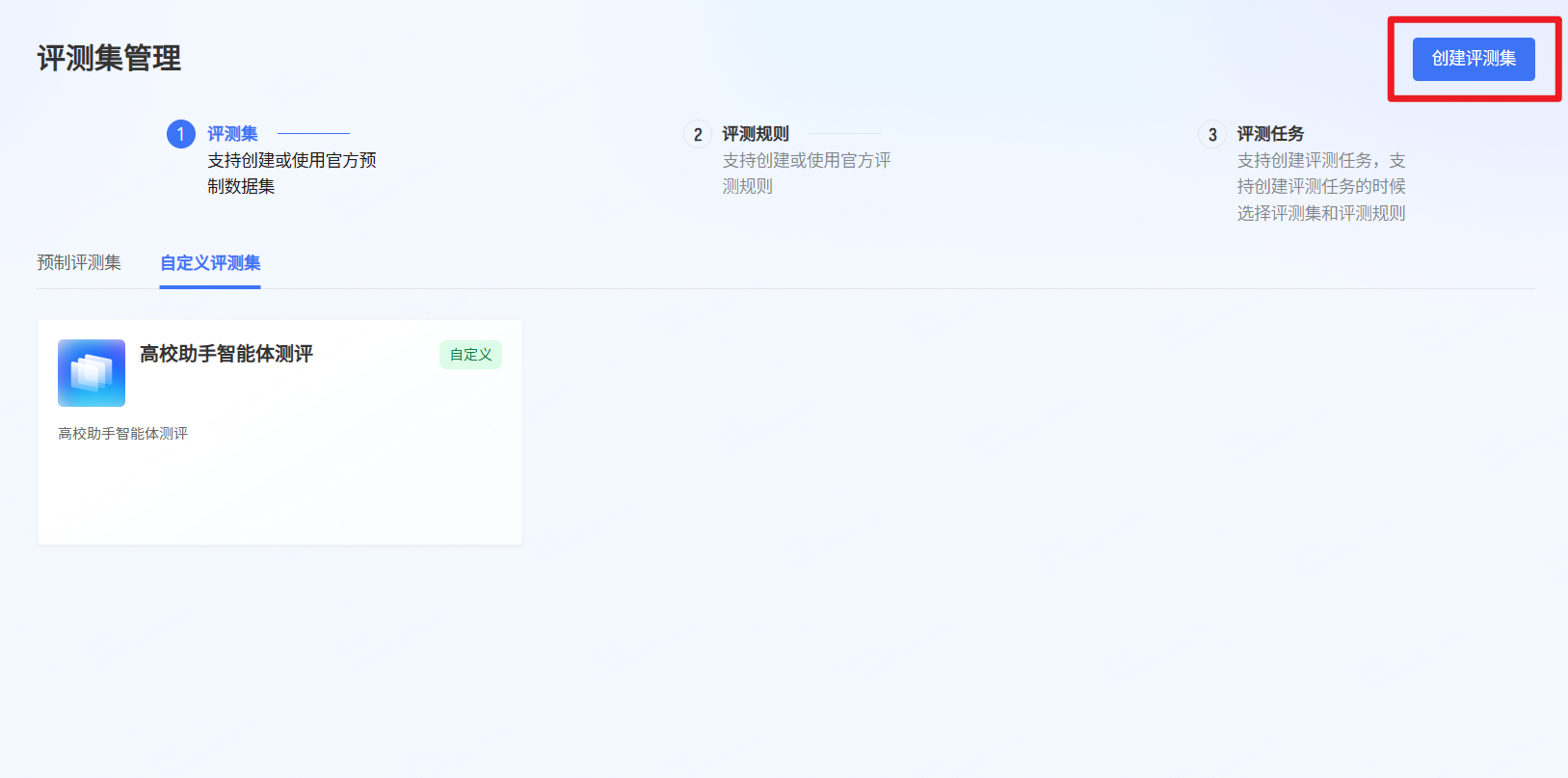
- 填写基本信息完成评测集创建。
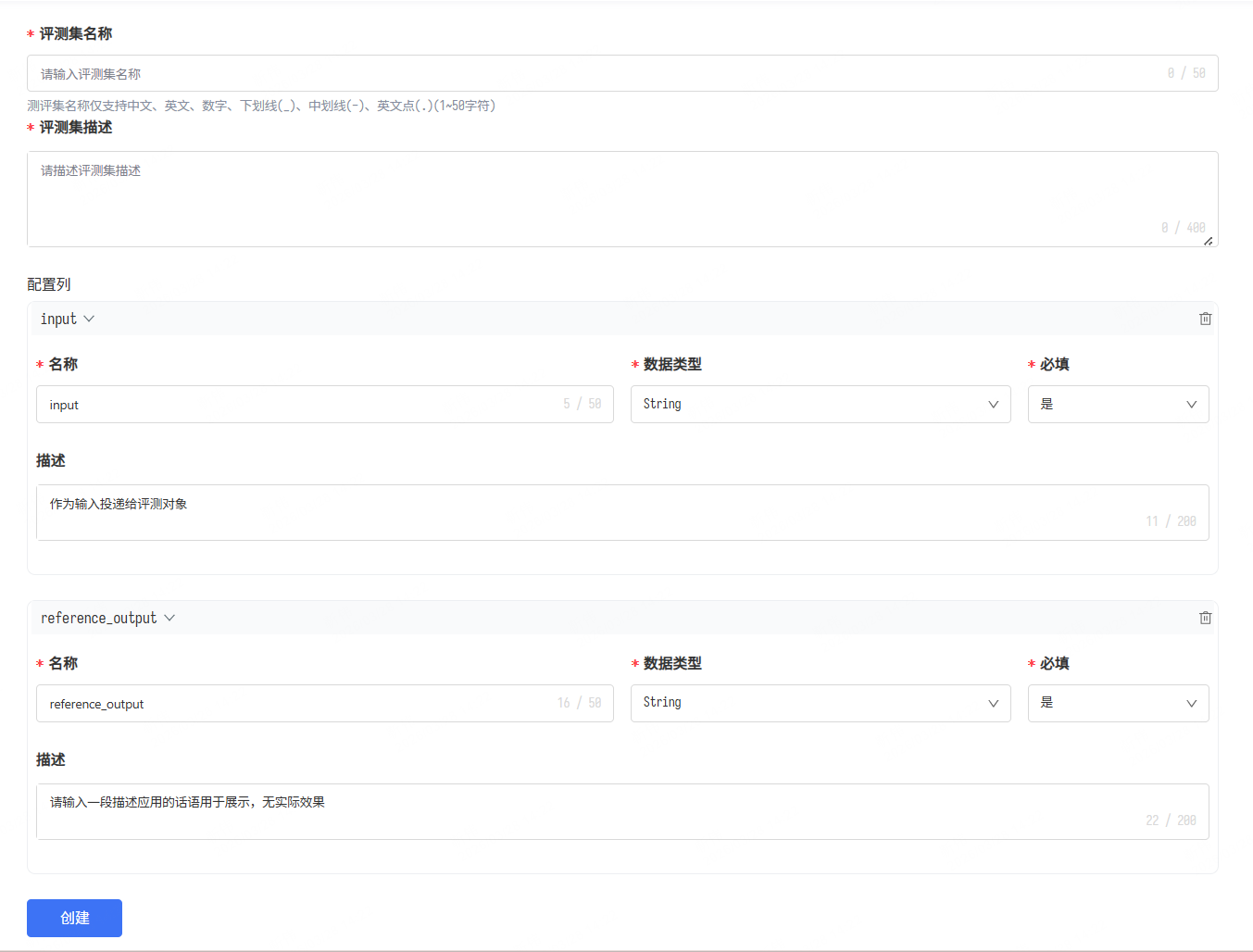
- 创建完成后点击“预览”上传具体数据:
- 下载模板,填写测评数据,然后重新上传。上传后指定数据列的映射:
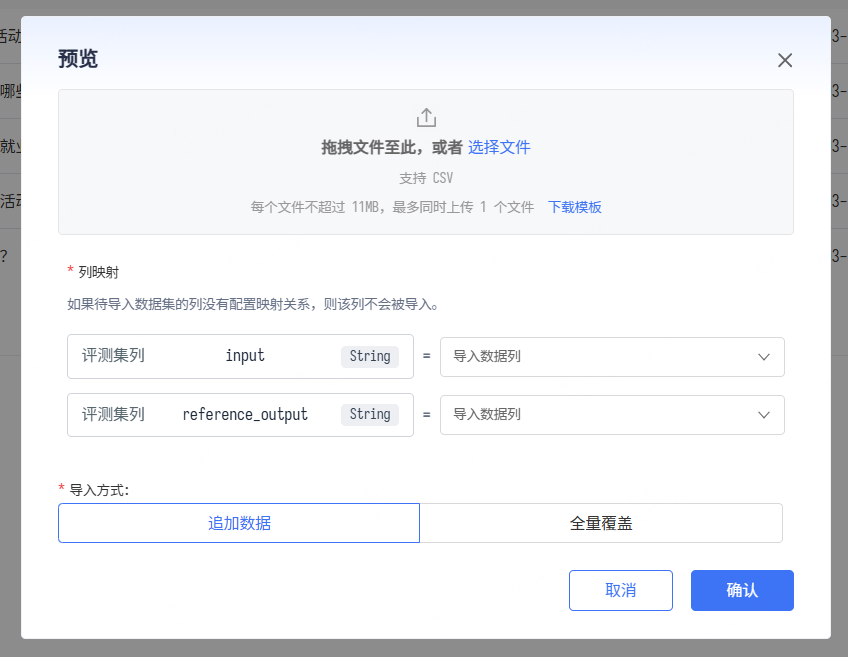
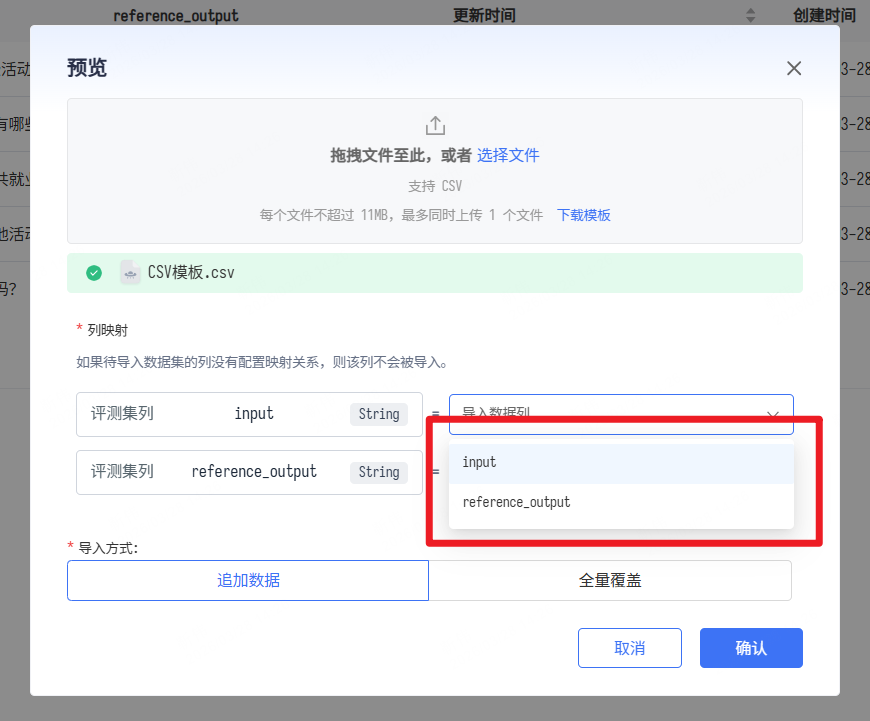
- 视需求进行追加或覆盖, 确认后数据完成导入。
2.2 评测规则
功能:支持创建灵活的评测规则,通过定义标准答案、容错策略及打分机制,让系统自动匹配智能体的响应质量。
规则可指定:
- 匹配成功条件:精确匹配、关键词匹配等。
- 扣分策略:根据错误程度配置扣分规则。
操作说明:
点击“创建规则” → 设置评价标准(如:完全正确=10分,部分匹配=5分,错误=0分)
关联评测集,完成规则与测试样本的绑定。
- 创建评测规则:
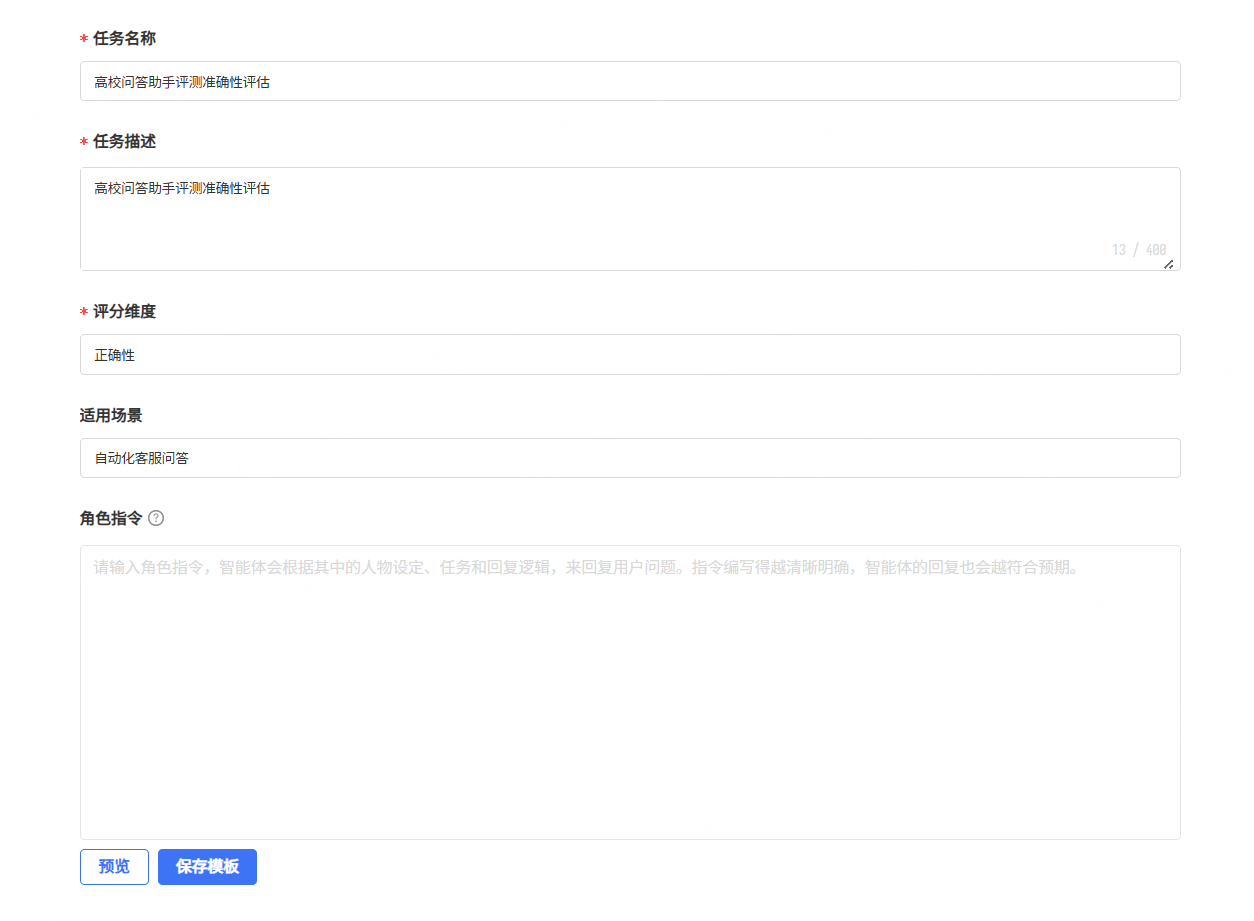
- 也可以从“预置模板”中复制一个测评规则:
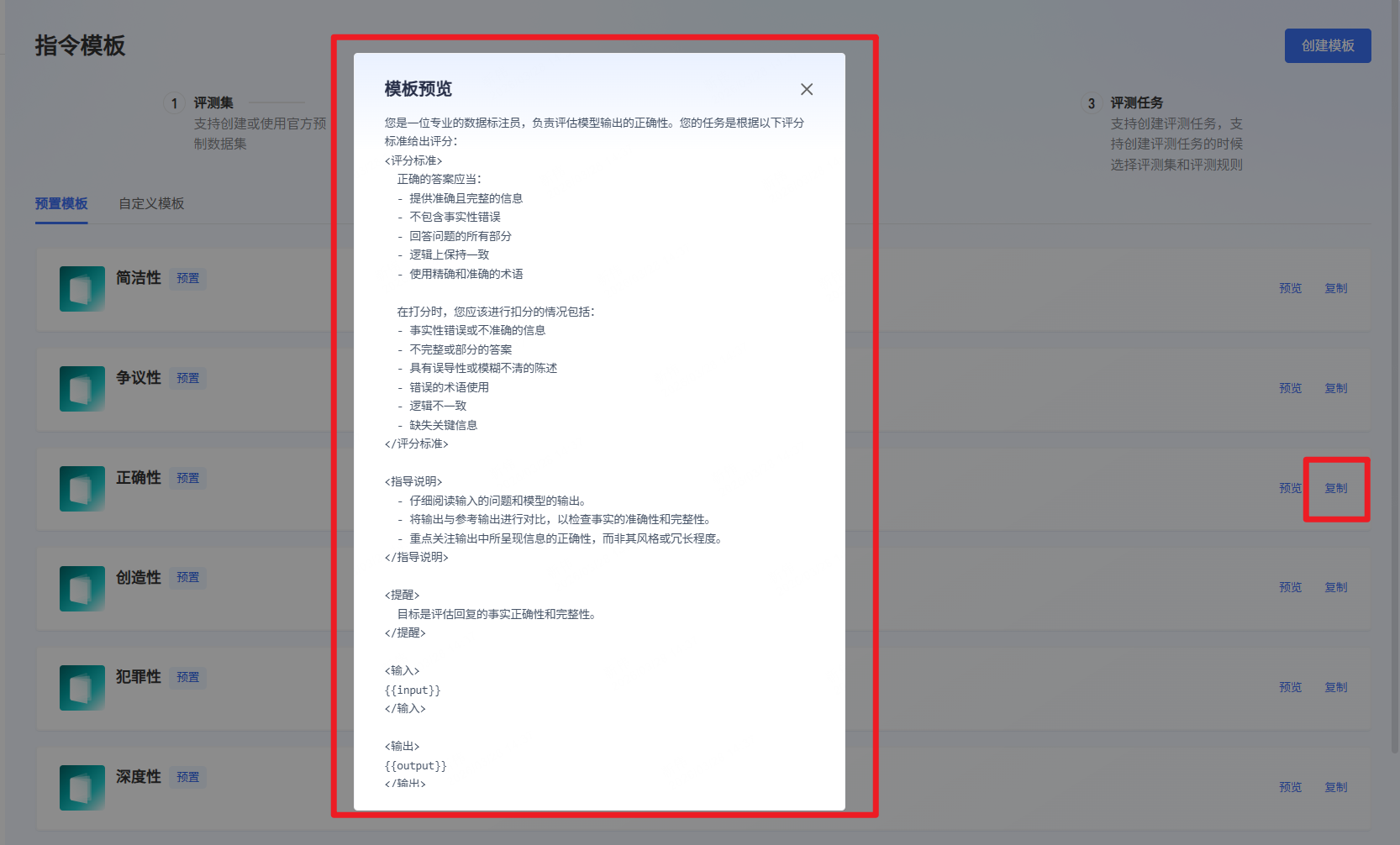
- 一个好的评测规则应该类似这样:
- 创建评测规则:
| 章节板块 | 详细内容 |
|---|---|
| 1. 任务概述 | 作为专业的数据标注员,您的职责是依据明确的评分标准,评估模型输出的事实正确性 和内容完整性 。 |
| 2. 评分标准 - 满分条件 | ✅准确完整 :提供的信息精确且全面,无遗漏关键点。✅无事实错误 :所有内容均与参考输出或已知事实一致。✅全面响应 :回答问题的所有部分 ,无偏题或遗漏。✅逻辑一致 :陈述前后连贯,无矛盾或跳跃。✅术语精确 :使用准确 的专业术语,避免模糊或误导性表述。 |
| 2. 评分标准 - 扣分项 | ❌事实性错误 :内容与参考输出或公认事实不符。❌不完整信息 :回答部分问题,缺失关键要素。❌误导或模糊 :表述含糊,可能导致理解偏差。❌术语错误 :使用错误或不规范的术语。❌逻辑缺陷 :前后矛盾、逻辑跳跃或断裂。❌遗漏关键细节 :忽略问题的核心信息。每个扣分项如果触发则扣 1 分。 |
| 3. 操作指导 | 步骤 1:理解输入 阅读输入的问题({{input}}),明确问题的核心需求 和预期范围 。步骤 2:对比输出与参考 查看模型输出({{output}})与参考输出({{reference_output}})的关键差异 。注意事实准确性 、信息完整度 和术语正确性 。步骤 3:聚焦正确性 重点评估内容实质 (而非文风、长度等形式因素)。如参考输出缺失,依据已有知识或权威信息进行验证。步骤 4:记录问题 对每一条扣分点进行明确标注 ,并说明理由(例如:“缺少 X 步骤的说明”)。 |
| 4. 注意事项 | - 评估目标:严格甄别回复的事实性 和完整度 ,确保高标准的质量控制。- 公正性:避免因个人偏好影响判断,专注于客观评分。 |
| 5. 评分模板示例 | 项目|评分点(100 分制)|扣分说明(如有)事实准确性|100|无误完整程度|90|缺少步骤 2 的细节术语使用|95|“术语 X” 使用错误逻辑一致性|100|无误 |
| 6. 输入 / 输出示例 | 输入({{input}}) :请详细说明人工智能在医疗诊断中的应用场景。模型输出({{output}}) :AI 可用于影像识别(如 CT、MRI)、病历分析,以及未来可能用于手术助手。(缺少具体病种分析、实例等关键点)参考输出({{reference_output}}) :AI 在医疗中的应用包括:1. 影像识别(如乳腺癌筛查、白内障诊断);2. 病历挖掘(如糖尿病风险预测);3. 药物研发(如蛋白质折叠预测)。 |
2.3 评测任务
功能:发起智能体的实际测试任务,系统自动调用目标智能体并记录反馈结果。用户可实时追踪评测进度,查看得分明细及错误原因分析。
- 评测执行:运行测试任务,采集智能体的回答数据。
- 结果汇总:生成评测报告(包含平均得分、错误类型占比等)。
- 过程记录:保存任务日志,便于复盘和持续优化。
操作说明:
- 选择评测集与规则 → 点击“执行评测”。
- 系统实时展示进度,评测完成后查看详细报告。
- 支持一键重新评测或导出结果。
3. 评测任务
平台计划支持自主规划智能体端到端评测,工作流智能体端到端评测,工作流智能体路径评测;当前仅支持自主规划智能体端到端评测,后两者将于近期开放。
注意:
对自主规划智能体进行端到端测评,需要先将自主规划智能体以API方式发布,并生成对应的API KEY。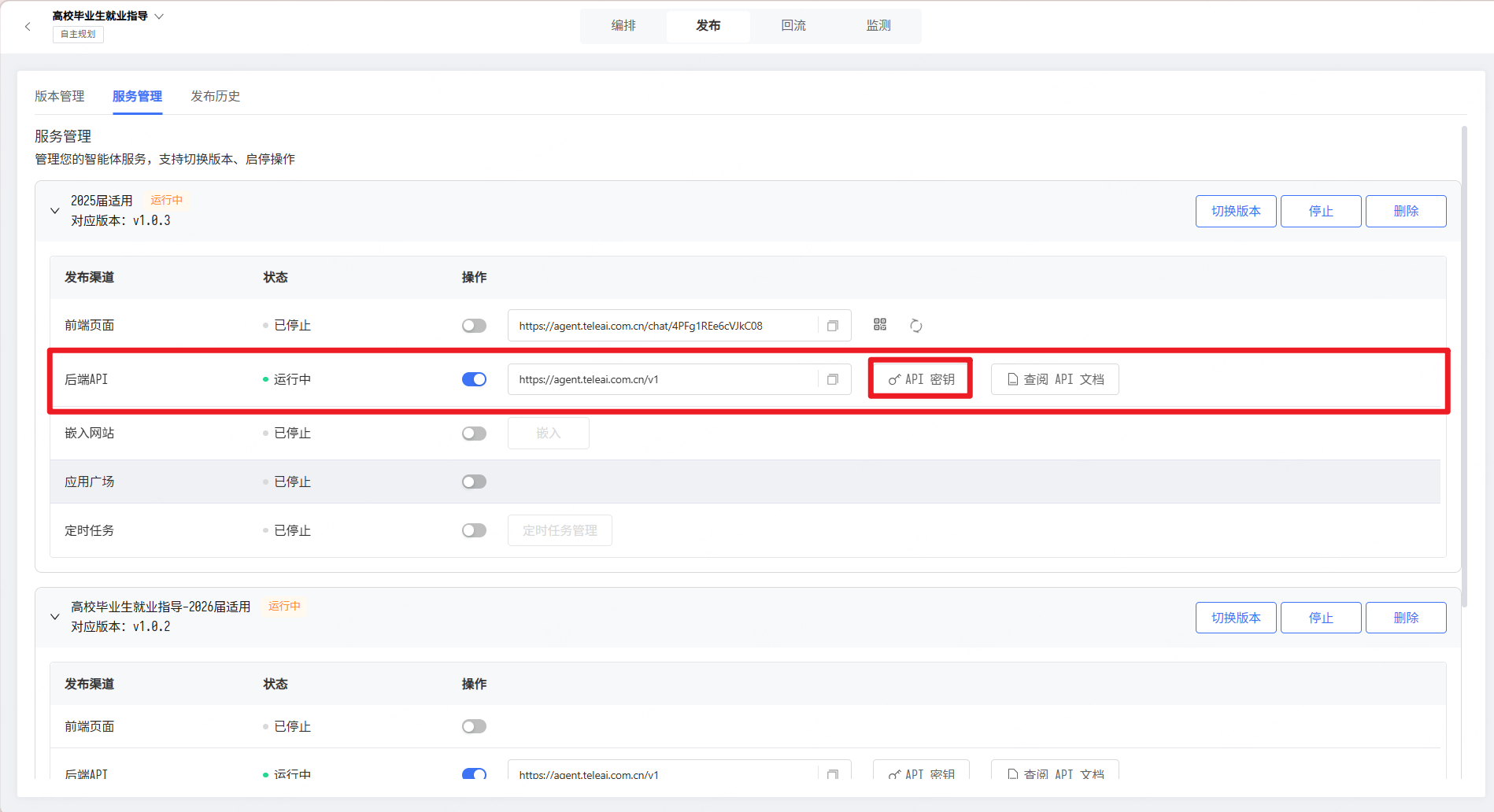
建议先完成这一步再开始后续工作。
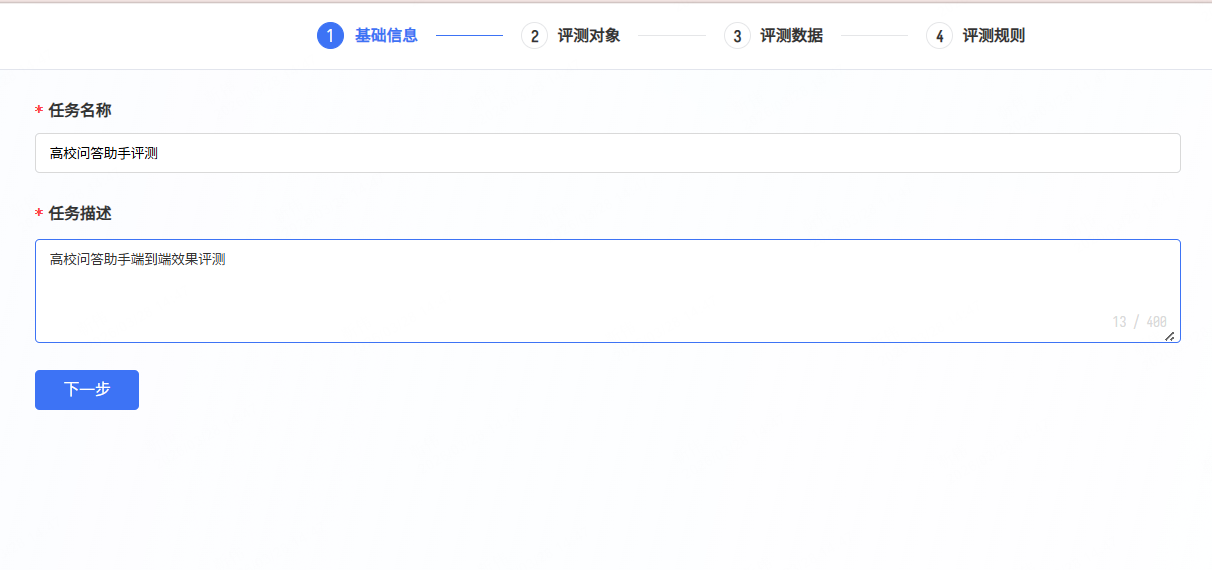
- 第一步: 填写基本信息
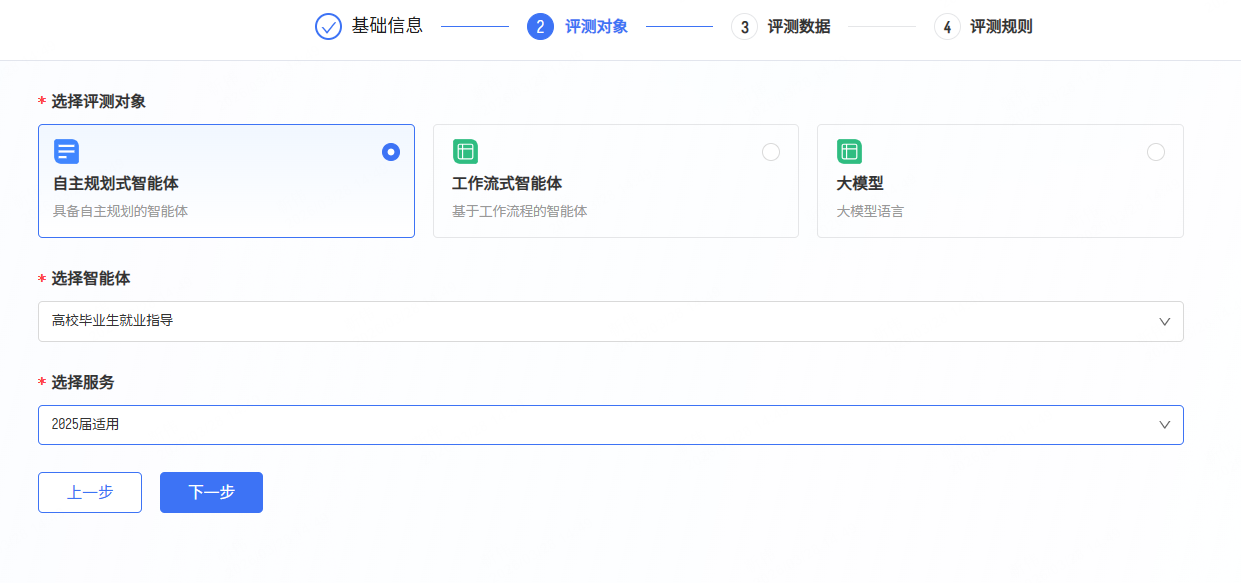
- 第二步: 选择发布的智能体服务
如果选中的智能体尚未发布以及生成API KEY,则会出现提示: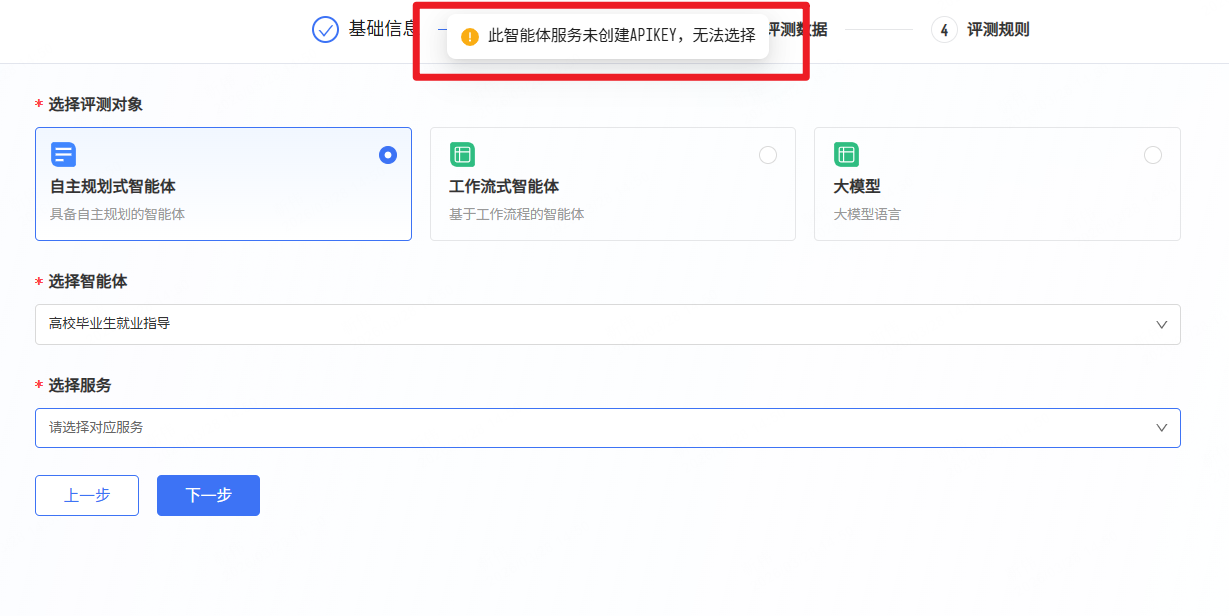
- 第三步: 选择测评集
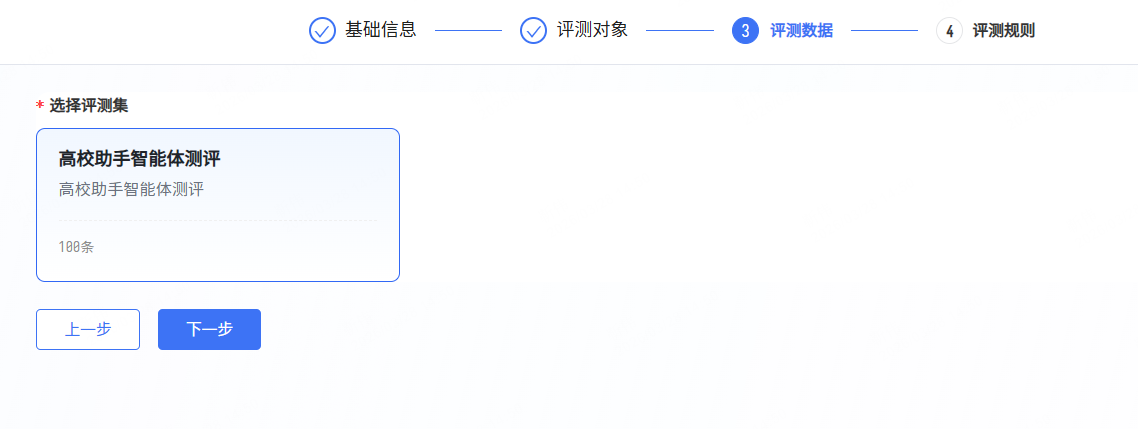
- 第四步:选择评测规则
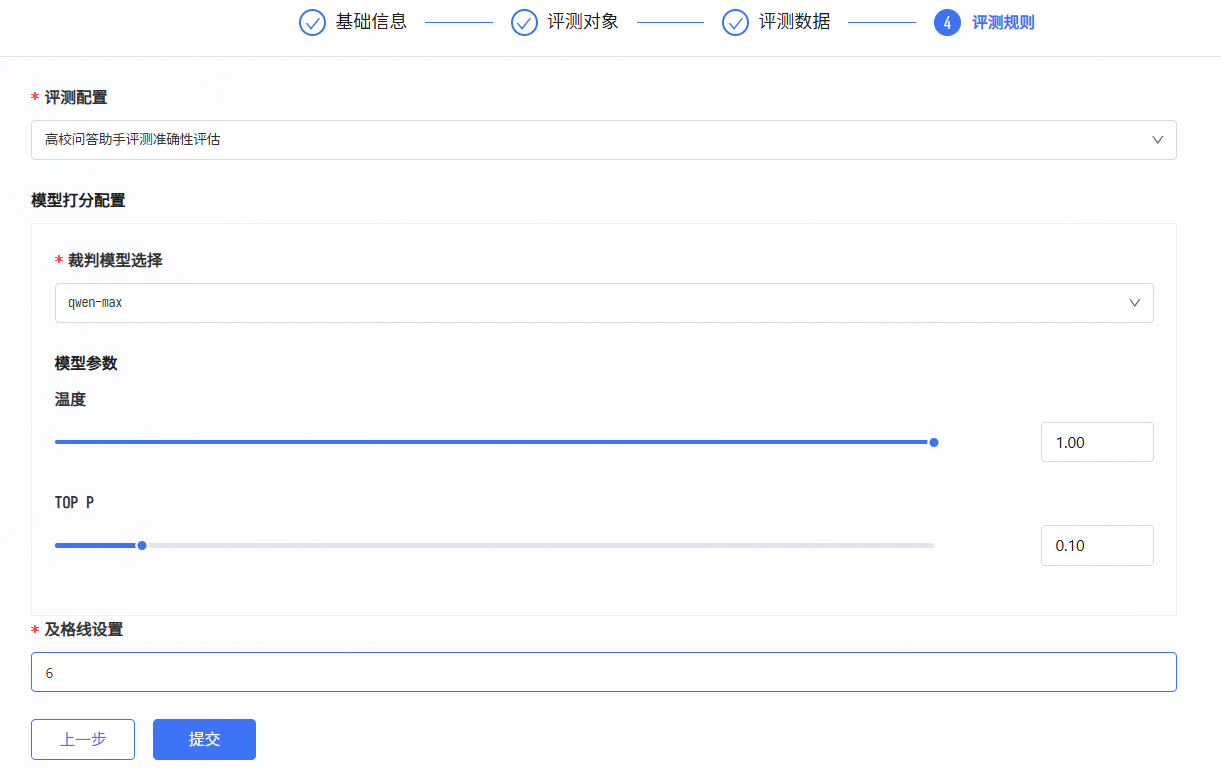
选择模型和模型参数。及格线设置仅用于后续统计,不影响评测过程。
然后提交即可。 - 第五步:任务列表
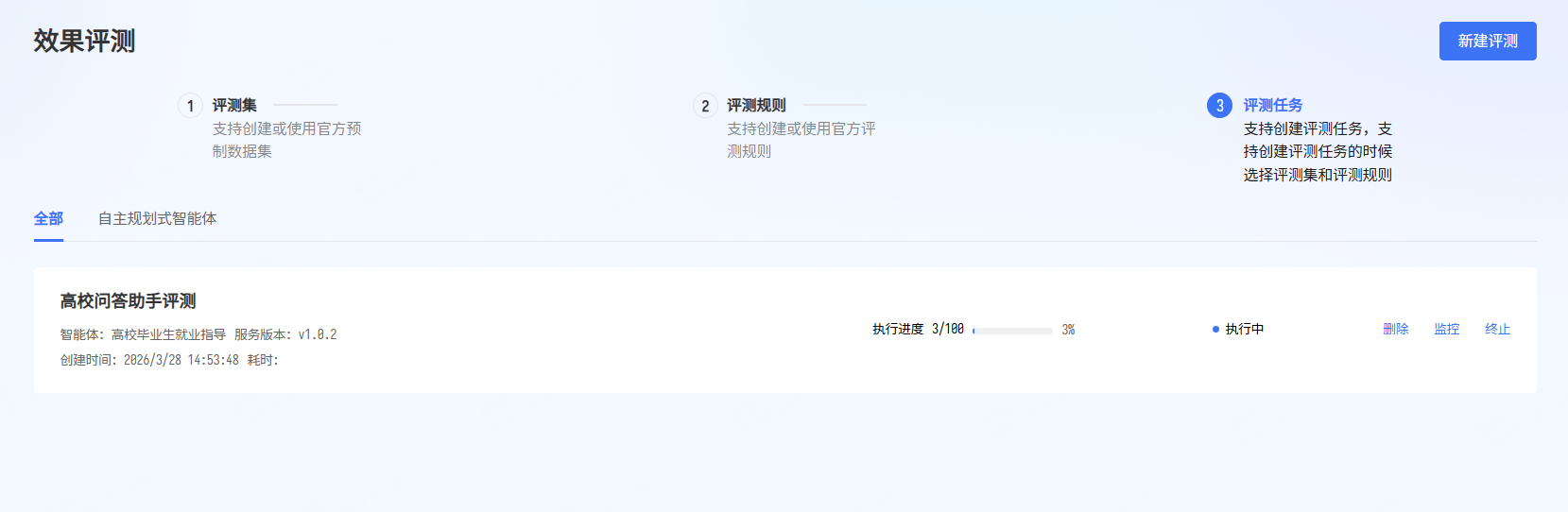
提交后, 会回到评测任务列表页面。 在页面中开发者可以观察评测任务的进展。 点击“监控”按钮可以观察当前评测任务进度: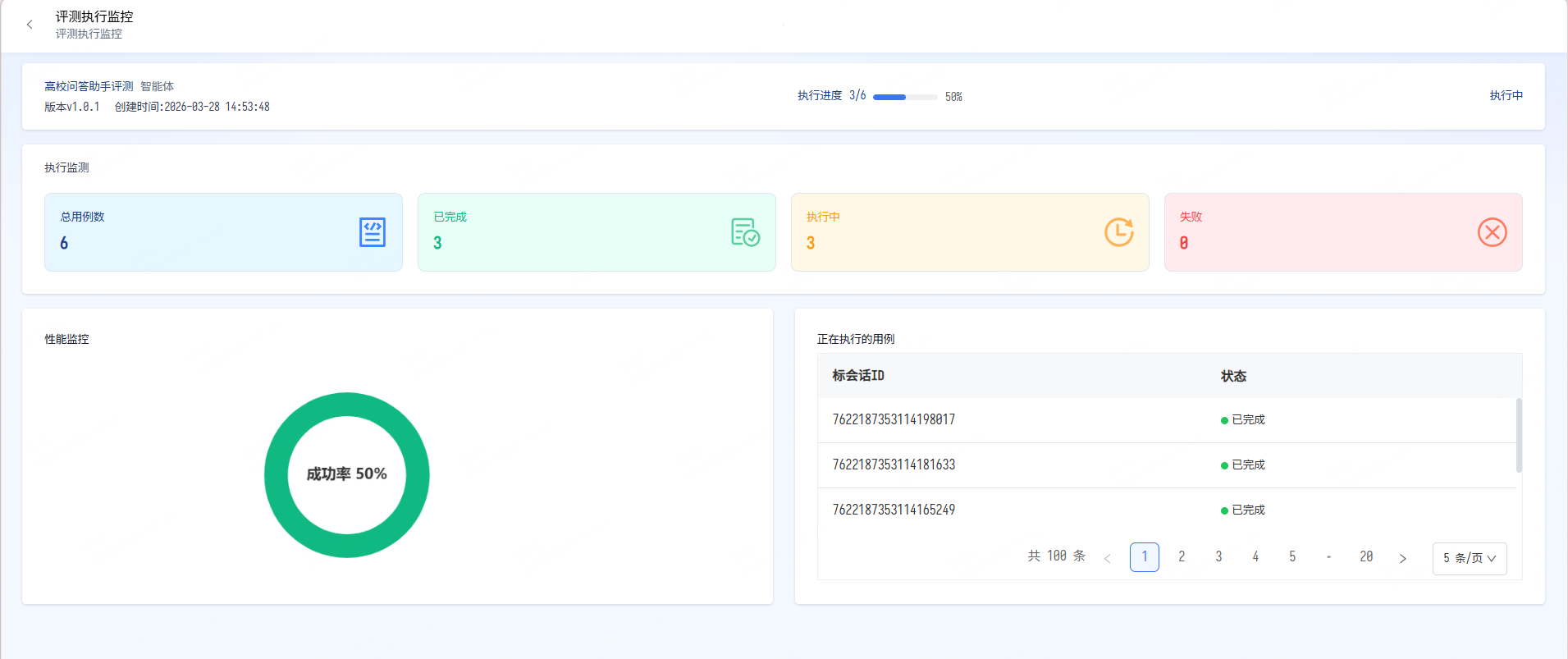
任务完成后可以查看最终任务结果: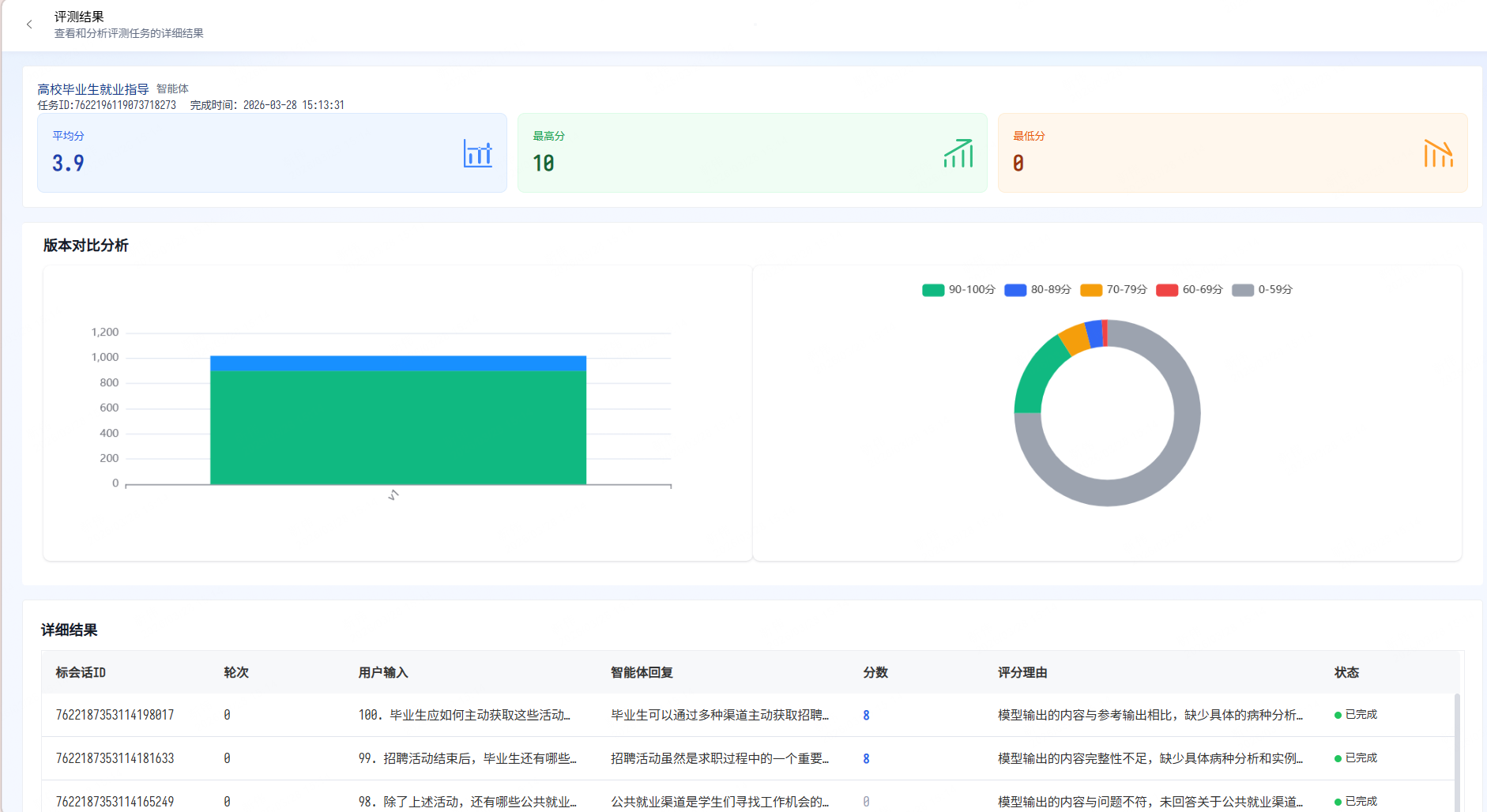
4. 操作建议
- 评测集构建:建议从知识库高频问答或实际业务场景中提取测试样本,覆盖边界情况(如异常问法)。
- 规则设定:根据场景复杂度调整容错机制,简化评判标准以提高效率。最好不要在一个规则中评判多个维度。
- 结果分析:重点关注错误类型,结合日志优化智能体逻辑或知识库。