



热门搜索
- 超多方言实时语音识别
- AIGC
- 语义大模型
- 智能体平台


 新闻详情
新闻详情国内首个!全国产化千亿参数细粒度MoE语义大模型开源!
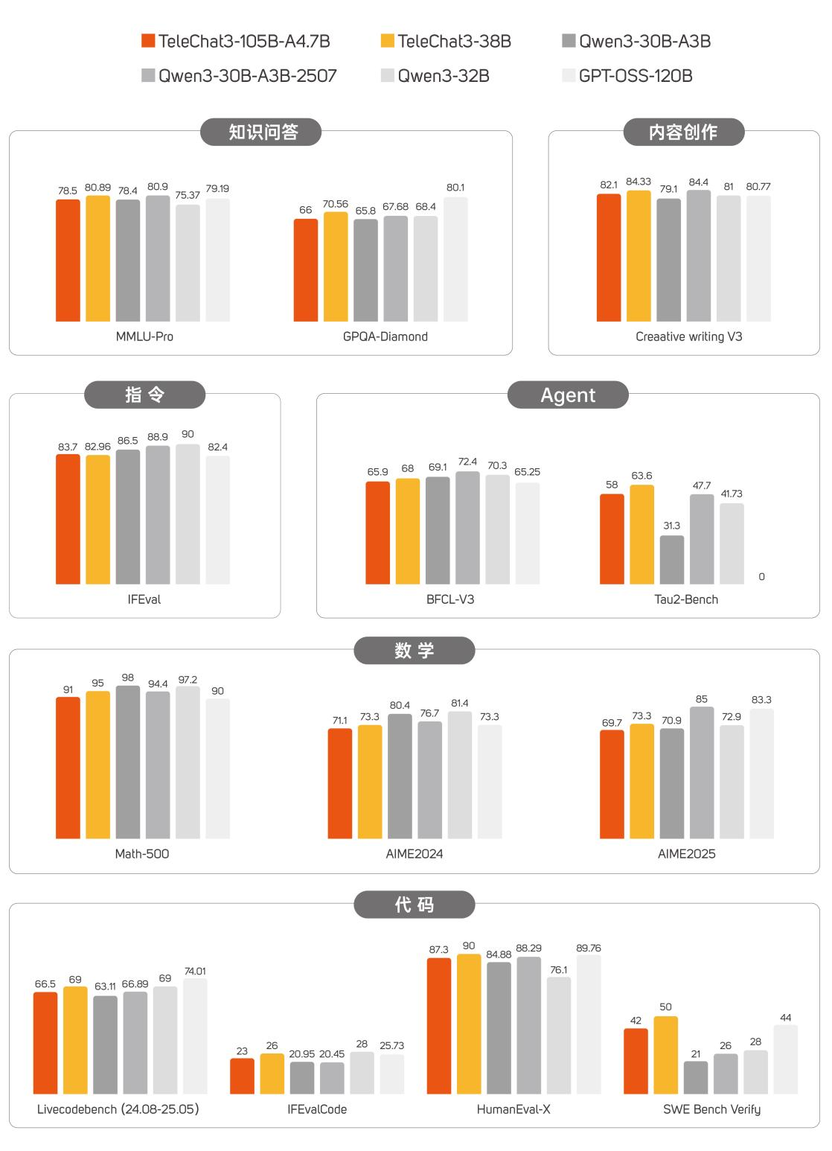
TeleChat3-105B-A4.7-Thinking,国内首个全国产化训练的千亿参数细粒度MoE语义大模型,正式开源!
问答、写作、数学、代码、Agent......多维度比肩业内头部!
面对综合任务场景,TeleChat3-105B-A4.7-Thinking 高效拆解任务需求,整合多项代码能力,一次性交付出完整可运行的代码。
省去大量人工调试时间投入,运行流畅,审美在线!
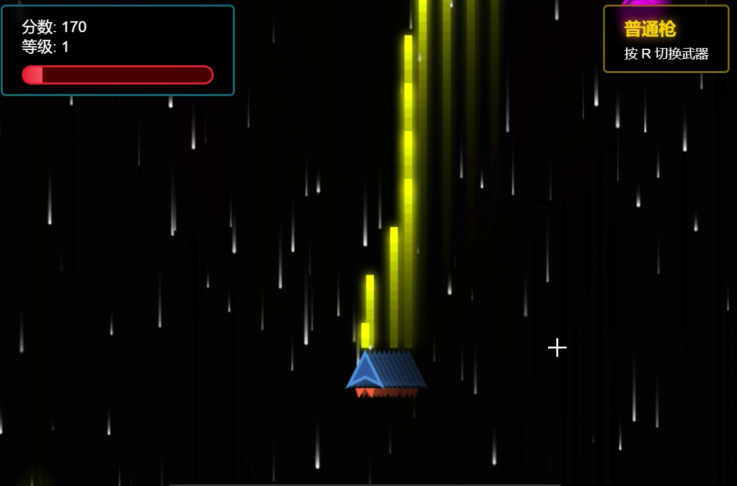
由 TeleChat3-105B-A4.7-Thinking 独立完成的射击类小游戏
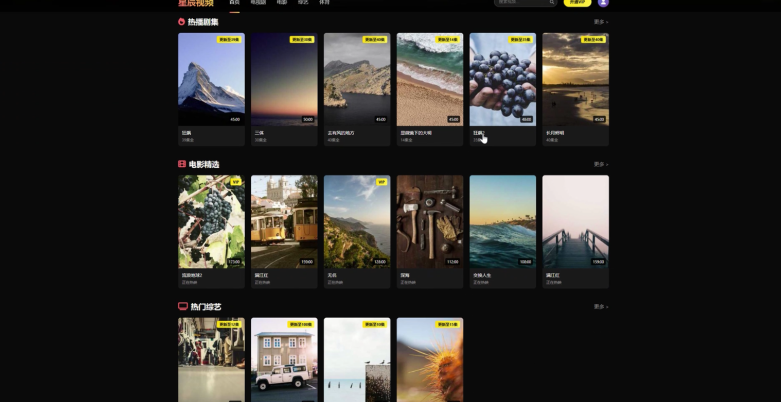
由TeleChat3-105B-A4.7-Thinking 设计的视频网站页面
此前,中国电信人工智能研究院(TeleAI)与中电信人工智能科技有限公司已陆续开源原创打造的 TeleChat、TeleChat2 及TeleChat2.5系列模型,以传统稠密参数架构为主,模型尺寸覆盖十亿到千亿,构建了全尺寸大模型开源布局。
上半年,星辰语义大模型的首个MoE架构模型TeleChat2-39B-A12B也正式开源,采用粗粒度MoE架构,初步实现知识模块化存储,按需唤醒相关专家模块。
为了进一步提升MoE 大模型的效率与性能,让参数利用更充分,在中国电信集团 CTO、首席科学家、中国电信人工智能研究院(TeleAI)院长李学龙教授的指导下,TeleAI科研团队以智传网(AI Flow)为理论基础,完成了TeleChat3-105B-A4.7-Thinking的全国产化训练。
该模型采用细粒度MoE架构,基础模型训练数据超10T,共包括1个共享转结案和192个路由专家(每次激活4个专家),模型整体共105B参数量,实际激活参数为 4.7B,专家稀疏比处于业界前列。
面对不同的任务类型,更加细分的专家子模块实现了术业有专攻,模块之间也实现了更精准、更任务导向的协同。
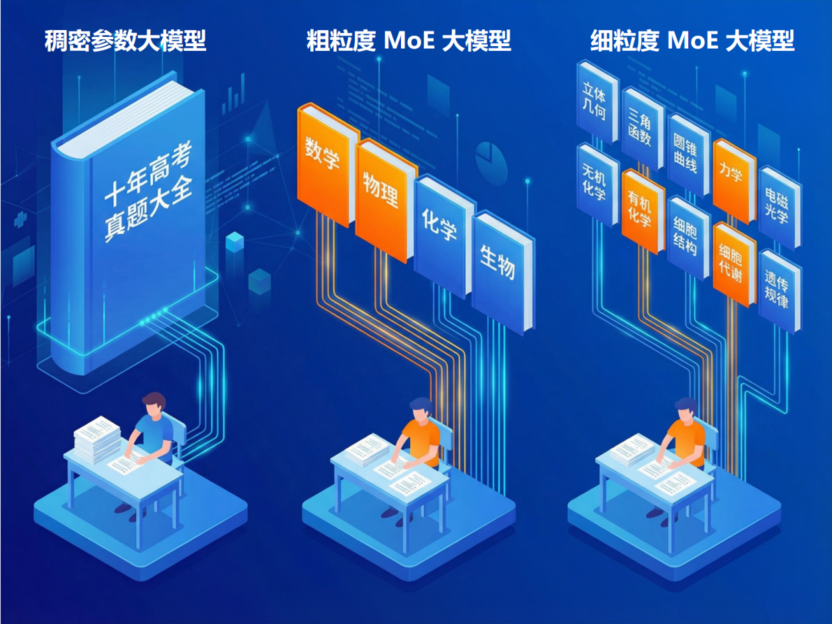
打个比方,假如大模型是个理综考生,稠密参数大模型就是从一本“十年高考真题大全”合订本里找思路,知识庞杂,效率低下。粗粒度模型,则实现了初步的学科分类和调用,减少了无效的知识调用。细粒度MoE,则是更进一步,特定的题目只调用特定的细分知识点组合,见招拆招,精准调配。
此外,TeleAI还同步开源了稠密参数模型TeleChat3-36B-Thinking模型,在知识、逻辑推理、智能体等维度实现了能力提升,并实现了文本创作、语义理解、角色扮演等任务的针对性优化。
训练方式创新
TeleAI 科研团队采用细粒度的模型初始化方式和学习率控制,对不同权重采用不同的初始化方式和学习率,加快模型在训练初期的收敛速度,增强模型在训练中的稳定性。
同时,采用课程学习的方式。
首先,聚焦低难度、高质量教育知识以及跨语言数据进行模型训练,以获得较好的模型初始性能和迁移能力。
其次,引入复杂数据,增大数学、逻辑推理、代码等数据占比,提升模型逻辑推理能力。
最后,使用高质量数据进行退火,持续提升模型效果。
在后训练阶段采用引入负载策略,在专家效果特化和专家负载之间进行权衡,减少热专家的同时保证训练效果。
国产算力优化
在 MoE 模块中,科研团队将Tensor并行域转换成专家并行域,从而将MOE的“All to All”通讯约束在节点内,提高通讯效率。
为了解决长序列训练时预训练文本拼接长度不一致带来的性能劣化,团队引入了micro级别的动态拼接,缓解计算负载的不均衡,减少了计算波动。
对于复杂的并行策略调优,则采用了自动并行工具来加速搜索、优化并行方式,节约搜索和调优成本。
目前,TeleChat3-105B-A4.7-Thinking 已经登陆 GitHub,欢迎开发者们前往体验!
开源地址: